Below I am describing one of the several ways to design a cloud file storage system such as dropbox or google drive. This design makes several assumptions to simplify details – a real production cloud file storage system will be a lot more complex.
Contents:
- Requirements: Describes the various functional and nonfunctional requirements of the system
- Storage & Capacity Estimate: Describes our storage and capacity needs
- API Design
- High-Level Design: Describes the high-level design of this system
- Consistency Requirements: Describes what it means for this system to be ACID compliant
- Client-Side Processing: Describe various local client services that manage the client files
- Client Local File System: Describes how files will be stored on the client file system
- Meta Data Service: Describes the backend metadata service which is responsible for maintaining the file metadata information
- Meta Data Database: Describes the tables behind the metadata service
- Chunk Service: Describes the chunk service which is responsible for maintaining file chunk information in the backend
- Chunk Database: Describes the database tables for chunks
- Block Service: Describes the block service which is used to persist the file chunks into the cloud store
- Notification Service: Describes the notification service which is used to transmit file change information to clients
- Handling Data Duplication: Describes how the system can reduce the storage space by avoiding data duplication
- Handling Conflicts: Describes how the system can handle conflicts during edits
- Use Case – Create New File: Describes use case for creating a new file
- Use Case – Share a file: Describes use case to share a file with another user
- Use Case – Modify a file: Describes use case to modify a file
- Use Case – Delete a file: Describes use case to delete a file
- References: Contains references that I used to come up with this design
Requirements
Functional
- Users can create, edit, delete and share files
- Users can share the files with other users
- Files are automatically synchronized across user devices and across users who have the file shared
- On mobile devices, file synchronization is on-demand
- The system should manage conflicts that result from files getting updated by users across devices
Non functional
- The system must be highly available and fault-tolerant across regions
- The design should scale under increased load
- Should minimize storage space needed on cloud and in addition minimize network bandwidth used
Requirements not covered in this design
- We are not applying a user-based quota in this design – we could have the user service ensure quotas are met
- I am not covering read and write permission semantics in this design – file sharing semantics are implemented, could extend file sharing to implement read and write permissions
- Offline file editing and updates impose design considerations which I am not covering here
- We are not covering billing in this design
- I am not covering across files text search capabilities but this is a really interesting problem that I will try to write another article on
Storage and Capacity Needs
Assuming we are supporting 1K organizations, each with 1million files that are on average 1MB in size. The total storage to persist this data is : 1PB. Replicated 3x this would amount to 3PB of data. We can classify the data based on usage into cold and hot data, for infrequently used data we can store it in cold storage and frequently accessed data in AWS S3 or similar storage. In addition, if we assume that 1% of the storage needs to be dedicated to meta data, that will amount to 300TB of storage for the meta data. Since we need to provide strong ACID properties around file consistency, it will be prudent to store the meta data in a relational database.
Assuming each org has 1K users, off of which 5% are concurrently using our system, we will need to support 50K concurrent users. Assuming a single server can support 1K users, we can distribute the load across 50 servers. If we assume servers are running at 30% of peak capacity on average, we will need 150 servers.
Its likely that a certain percentage of files are commonly accessed by organizations. We can store these files in distributed memory. If we assume that commonly accessed files amount to 0.5% of total file, we will need 150TB of distributed memory cache for file storage.
In addition, we can benefit from storing meta data for commonly accessed files in memory. We can decide to store 10% of meta data in memory and thus will need 30TB of memory for meta data storage.
API Design
POST /file/
Request Json : {fileName, numberAndSizeOfchunks}
POST /file/{fileName}/{chunkid}
(post chunk data for a file)
GET /file/{fileName}
(get file meta data for a certain file)
GET /file/{fileName}/{chunkId}
(get a given chunk for a file)
PUT /file/{fileName}/{chunkid}
(update a given file chunk)
DELETE /file/{fileName}
(delete a certain file)
GET /list/{filePath}
(get list of files at a certain path)
POST /share/{filePath}/{otherUser}
Request Json {permission-type}
(share a file with another user while specifying permission credentials)
DELETE /share/{filePath}/{otherUser}
(stop sharing a file with another user)
High Level Design
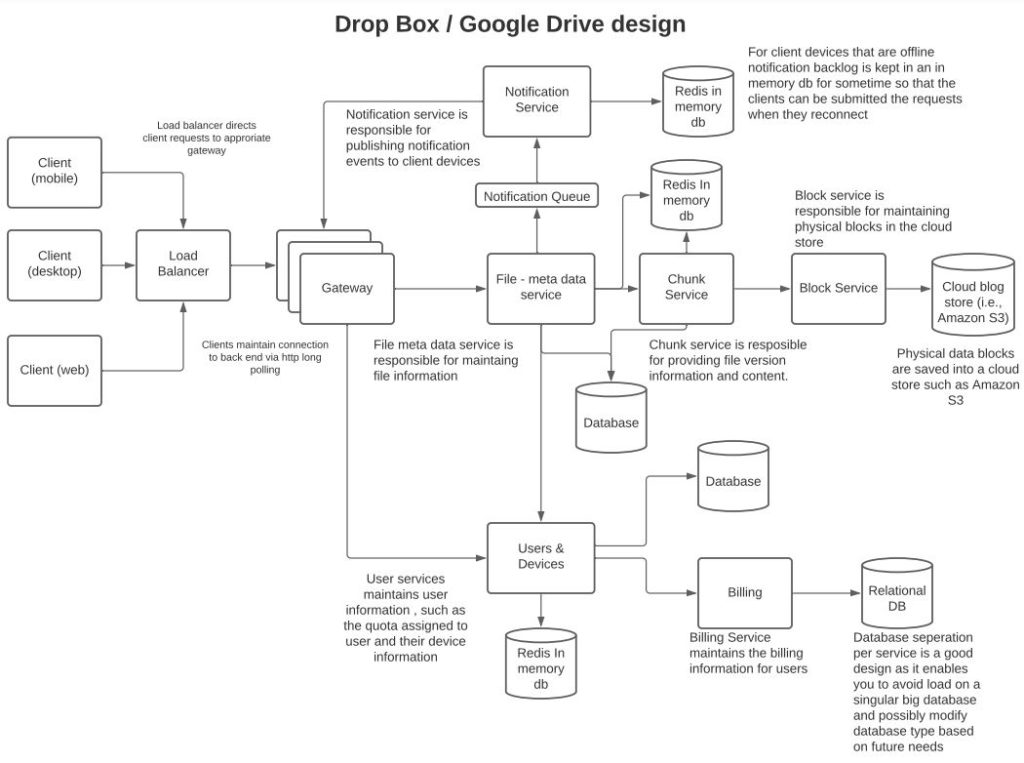
Clients maintain the files in a local file system. Clients publish compressed deltas (changed blocks) to the backend to reduce network traffic and latency. Metadata service stores file information in a database. Chunk service stores information pertaining to chunks in a database. The physical file blocks are saved by the block service into cloud storage. File changes are notified to other clients via the notification service.
User and device information are managed by the user and device service. This service maintains user entitlements related to how much storage space the user has and the device list of the users. The billing service is responsible for managing fee information.
Consistency Requirements
The design will support the ACID properties related to simultaneous updates.
Atomic: File updates should be processed in an atomic manner. This means that if a user updates a file on one device, the changes should be synchronized on another device for that user into first a temporary file, and once the temporary file has been completely updated, the file link can be updated to point to the new file atomically.
Consistent: This means that users will see files in a correct state albeit be it with some delay across users and devices. For example, if a user deletes a file on one device, other devices for that user will get an update indicating that the file has been deleted. Similarly, if a user edits a file on one device and moves to another device to begin editing the file where it was left off, the user will see the file in the same state where it was left on the first device.
Isolation: Changing the state of one file will not interfere with other files in the system. However, it’s possible to make changes independently on two offline devices. Later if a user brings one of the devices online and commits and repeats the same on the second device, the user may get a conflict error. See more on handling conflicts in the conflict handling section.
Durable: Once a file is saved the data should not be lost. This is achieved through cross region replication. Changes in the database in one region are replicated to the other region and thus having copies of data across multiple regions ensures that in the event that a region goes down data is not lost.
Client Side Processing
- File system watcher: The process monitors the file system for changes and when it notices a change in a file or directory it identifies to the indexer to process the file change. On Linux, it can use INotify to process the changes.
- Indexer: The indexer receives a notification from the watcher that a file has been modified. It uses the chunker (below) to identify blocks that have been modified. And communicates those blocks to the client synchronizer for the client synchronizer to synchronize those blocks with the back end.
- Chunker: The chunker splits the file into smaller blocks such that the changed chunks can be efficiently communicated to the backend.
- The size of the chunks can be determined based on the file size. For example larger chunks for larger files and smaller for smaller-sized files.
- Chunks should also be based on the client size internet connection. If the connection is slow then smaller chunks should be used so that the request doesn’t result in timeouts.
- Client-synchronizer: The client synchronizer is used to communicate with the back end for file changes from other devices and to push changes from the current device to the back end.
- Can use long polling instead of WebSockets for the communication with backend as dropbox design doesn’t need updates to immediately be transmitted across devices.
- It can use a file differencing algorithm to detect chunks in a file that have been modified and only submit those chunks to the backend.
- To reduce network bandwidth consumption the synchronizer can compress the chunks before submitting them to the back end.
- Client-side metadata: File metadata can be kept in a local database such as SQLite. File metadata should include the directory structure of the file starting from the root. For each file, its name, time created, size of the file, number of chunks, size of chunks should be stored, and for each chunk, a hash uniquely representing that chunk should be stored.
Client Local File System
Files can be managed locally on the client in form of a UNIX directory structure. Under the root directory, we can create a proxy sub directory that contains a list of files that other users have shared with the given user to easily view shared files within the user’s directory space.

The above diagram indicates how the file structure on the client device will look. Here ‘User A’ has shared the folder ‘Folder languages’ with user B. Shared files appear in the file system under the folder ‘Shared-Folder’ that sits under the root. This can enable users to quickly identify all shared folders.
Meta Data Service
This service is used to maintain the file structure in the metadata database tables. When users push file system changes to the backend, this service persists those changes to the database. It is also responsible for managing sharing of files between users. When a user shares a file with another user, this service will insert that change in the database and transmit the change to other users via the notification service.
Meta Data Database
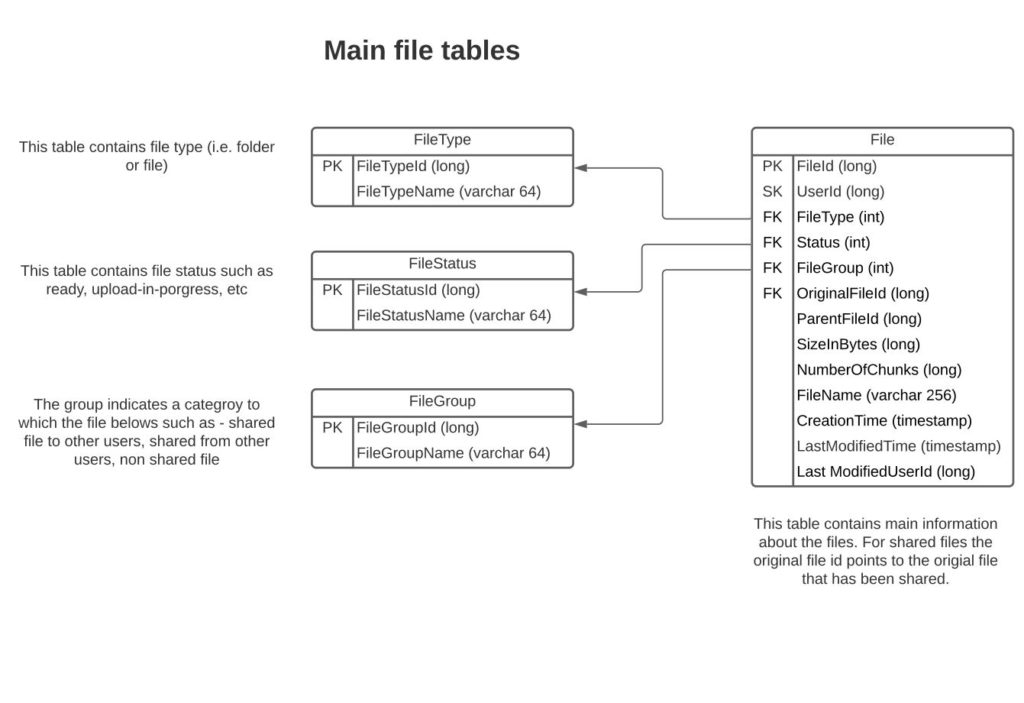
See the main file tables above. There are multiple ways to construct these tables. And there are a lot more tables needed for a comprehensive setup. I have explained above just one of the ways to set up a few core tables.
The idea here is that each file contains a link to the parent file id and thus a file structure hierarchy can be established via recursing the parent files. Another approach could be to establish for each file its child files in another table but that will create slightly more complexity.
There are multiple ways to shard the file table. One of the ways would be to shard the table by UserId. This would enable all files belonging to a given user to live on the same shard. However, the downside is that for shared files another query will be needed to retrieve the original file from another partition.
Another enhancement in table structure could be to make the tables bi-temporal so that clients can see historical metadata information of the files. Managing bi-temporal data adds slightly more complexity and I am not going to describe the bi-temporal table schema setup here. See more about bi-temporal table design on Wikipedia here.
Chunk Service
When file content is updated or a new file is created chunk service stores the file chunk information in the database and pushes the physical chunks to the cloud storage via the block service. It provides:
- For each save, stores a new series of modified chunks as an overlay on the previous chunks – see database table below
- Maintains file versions and returns prior versions of a file if requested
- Contains links to block store where the physical chunks are stored
To limit the amount of data being saved, a policy could be created to keep only the last X (i.e. 10) versions of a file and delete prior versions. As new saves are done chunk service can manage that asynchronously.
As indicated in the client-side synchronization service, only those blocks in the file that have been modified are transmitted to the backend. The chunk service can detect if these blocks match any that are already persisted and if so de duplicate by reusing the URI to existing blocks in cloud storage.
Chunk Database tables
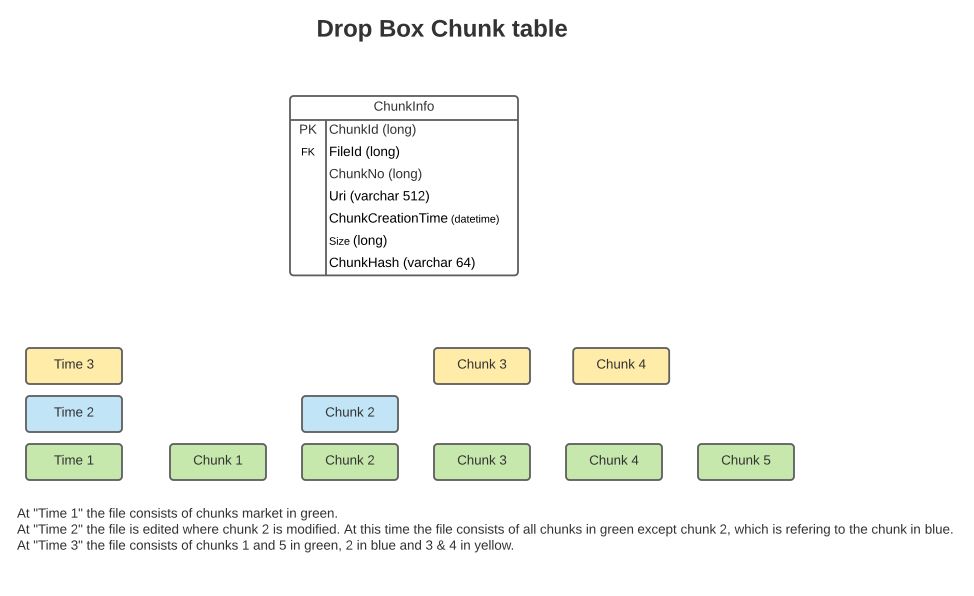
A file consists of a sequence of chunks. The ‘ChunkNo’ indicates the sequence of the chunk. The table also contains a URI to the physical store where the chunk is stored. A chunk is uniquely identified by its hash. FileId points to the file which owns this chunk. The CreationTime is the time when the chunk was created, it can be considered as an increasing number identifying the version no of the chunk.
The above diagram shows different versions of the files at times 1, 2 & 3 as consisting of various chunks.
Block Service
Chunk service communicates physical chunks to the block service, block service encrypts the chunks and pushes them to cloud storage.
Notification Service
Once file changes have been committed to storage, the metadata service publishes the changes to the notification queue. Notification service picks the changes from the queue and pushes the notification events to the client devices.
For devices that are offline, the changes can be kept in an in-memory data store for some period such that they get submitted to the client device when it reconnects.
Handling data duplication
Since we are storing the contents of files in chunks, where the hash of the chunk uniquely identifies that chunk we can store the universe of hashes in an in-memory cache, and whenever a new chunk is being saved by the block service, the block service can check if the chunk already exists and if it does point to the already existing chunk rather than creating a new chunk.
Handling conflicts
Each file can have a unique monotonically increasing version number that specifies the current version of the file. In case two users try to save the same file at the same time, one of the requests will get processed first. When the second request is getting persisted, we can check the version in the request against the current version inside the database transaction. If the versions don’t match we can return a conflict error to the user and have the user resolve the conflict.
To reduce conflicts the system can :
- Allow users to lock the file when editing
- Merge changes continuously from current edits by other users into the file being edited by the user
- In case when conflicts occur while editing, identify to the user that the conflict has occurred while the user is making the edits
Use Case – Create New File
The file is first saved on the client’s device. Client synchronizer writes the state of the file to the local metadata database on the client. The synchronizer calls to chunker service running on the local client to split the file into chunks. The synchronizer then pushes the compressed chunks to the backend where the file metadata service writes the file to the metadata database and communicates with the chunk service on the backend to save the chunks into the database and physical file content into the cloud backend. The file creation event is published to the notification service which pushes the file information to clients’ other devices.
Use Case – Share a file
When a user shares a file with another user, the client sends a message to the metadata service which persists the shared information into the database and pushes the change on a queue to the notification service, which will publish the file information to the devices of user with whom the file has been shared.
Use Case – File Modification
The client runs a differencing algorithm to identify chunks that were changed. It then compresses the chunks and sends the compressed chunks to the backend. The chunk service deduplicates the chunks and pushes them to the physical cloud storage. Chunk service calls the metadata service to find all users and devices who have the file shared and sends a notification to those users regarding the file update. The client devices can then pull the latest version of the files from the backend.
Use Case – Delete a file
When a user deletes a file from the local file system, the message is communicated from the synchronization service to the backend where the metadata service deletes the files and calls chunk service to delete the chunks belonging to the file. In addition, for all chunks which were not shared with other files a call is made to block service to delete the chunks from physical storage. The metadata service gets a list of users with whom the file was shared and removes the file from their shared file space. In addition, the metadata service makes a call to the notification service to notify other users with whom the file was shared that the file has been deleted.
References
System Design Interview – Alex Xu