High level rate limiter design
The purpose of limiting requests is to:
- Prevent DOS attack
- Ensure the system is not extended beyond its capacity so that it runs stably
- When the system reaches peak utilization during heavy load, resources should be diverted to critical services
Capacity Estimate
Storage space one user :
- 8 bytes user id
- 8 bytes window start time
- 8 bytes previous window count
- 8 bytes current window count
Thus per user we will need to store 32 bytes of data , add 16 bytes of data as overhead for the key value in memory hash based structure to make total per user space as 48 bytes.
Assume we need to provide rate limiting for 100 million concurrent users. This will require 4.8GB of memory. Replicated 3x it will be 15GB.
If we assume that a read write request to distributed memory takes 5ms then a single thread in 1 second can process 200 requests. If we run 10K threads on a commodity machine , estimating 2MB per thread, we will need 20GB per machine, allocating 12GB additional memory for OS, a 32 GB machine would suffice. Based on the calculation a single machine with 10K threads can support 2 million QPS. Assuming we need to support 100 million QPS, we will need 50 servers at full capacity. If we keep our servers are 30% capacity, we will need 150 servers.
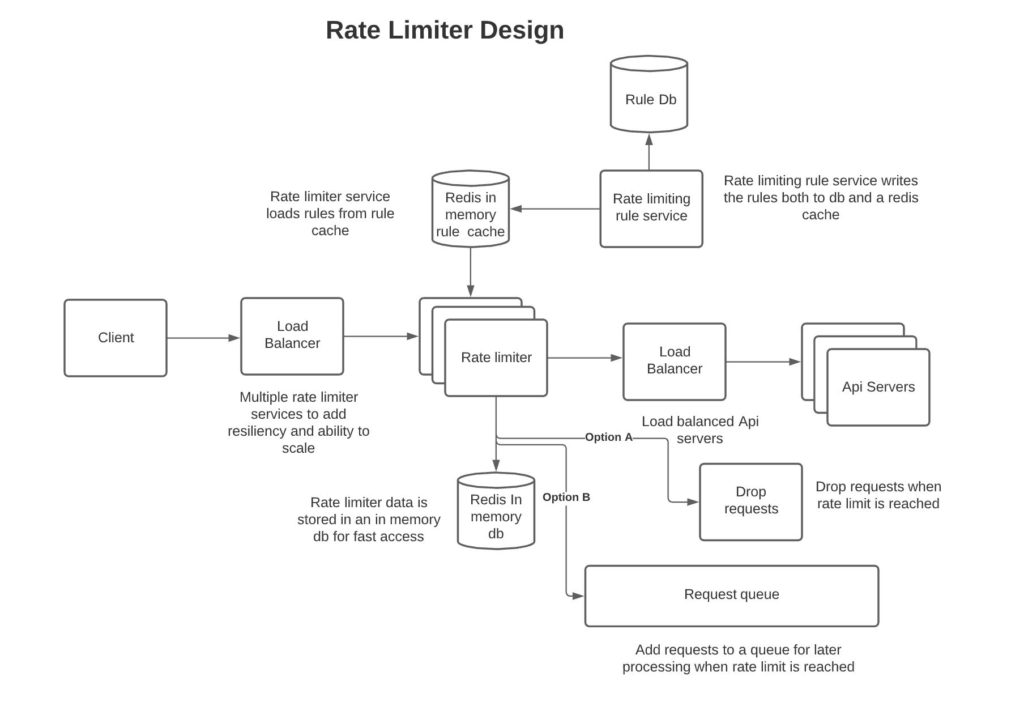
High level rate limiter design
Below is a design diagram of how a rate limiter can be applied. Please note here that a load balancer is used to create more resiliency and scalability. Redis is used for fast access, and via sharding, rate-limiting nodes can be pointed to the same Redis node, thus enabling multiple rate-limiting nodes to run concurrently. Rate limiting rules are persisted in a database and loaded into an in-memory cache for fast load. Rate limiter service loads the rules in memory with a time to live threshold such that the rule expires after a certain time, and the rate limiter service has to reload the value from the cache. This is done, so that rate limiter service keeps up to date with changing rules.
Rate Limiting Algorithms
Sliding window counter: There is a hybrid approach combining sliding window logs and fixed window counter. A distributed in-memory table is used so that multiple rate-limiting services can access the data and because reading from a distributed in-memory DB is faster than a physical DB. Time windows should be based on a consistent monotonic time rather than local rate limiter service time. This is so as to prevent miscalculations due to time drift.
The approach has the below logic.
- Manage per user count of requests in window based on time and request frequency in a distributed in memory table
- Update count in current window – increment by 1
- Delete time windows in the in memory table that are older than current-time-window – 1
- Calculate total hits as: hits in current time window + hits in prior time window * (window duration – (current time – current window start time)) / window duration
- If total hits are less than the threshold allowed, process the request else reject the request
Pro:
– Uses less memory than fixed window log
– Isn’t prone to spikes at the edge of the previous window as it averages the count of requests in the previous window
Con: It assumes the distribution of hits in the prior window was uniform. For example, it’s possible that the frequency of hits at the beginning of the prior window was significant, but then there were no hits near the middle or end of the previous time window. But we still account for all the hits in the prior window even though, strictly speaking, the hits at the beginning of the prior window should have been discarded. However, this approach is likely a decent compromise due to its memory usage, simplicity, and reasonably thorough logic.
Sliding window logs: The approach calculates the exact number of requests per user by time and thus is the most accurate. The requests per user can be saved in a Redis sorted set, where per request values in the sorted set before the allowed time window are deleted. Then the total number of requests in the time window is checked. If within the threshold, the request is allowed to pass. Otherwise, it is stopped.
Pro: This type of rate limiter is very accurate
Con: Uses a lot of memory as it stores every user request in a distributed in-memory DB (i.e. Redis).
Fixed window counter: The approach divides the time into buckets and calculates the hit count per bucket. When the hit count in the current bucket exceeds the threshold, the requests are dropped until a new time window starts. Memory can be trimmed by deleting expired time windows.
Pro: The logic is pretty simple, and it doesn’t use a lot of memory.
Con: Is prone to heavy hits at the edges of the time window. For example, if the quota in a time window is 100 and 100 requests came just at the end of the previous time window, but a new time window just began, and therefore new requests are allowed in as a new time window resets the count of the hits.
Token bucket: This is a commonly used rate limiting algorithm. The idea is that you have a bucket with predefined capacity (tokens). The tokens in a bucket get filled at set rates. Once the bucket reaches capacity, no more tokens are added. Each request consumes tokens from the bucket. If the bucket is empty, the request can’t be processed; otherwise token in the bucket is decremented, and the request proceeds.
Pro:
- This is a simple and well-understood algorithm.
- This is memory efficient.
Con:
- Some tuning around bucket capacity and refill rate is needed to best utilize the algorithm.
References
Please see the links below for a detailed explanation of rate limiters:
https://cloud.google.com/solutions/rate-limiting-strategies-techniques
https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling-9304b0d18250
https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
https://stripe.com/blog/rate-limiters