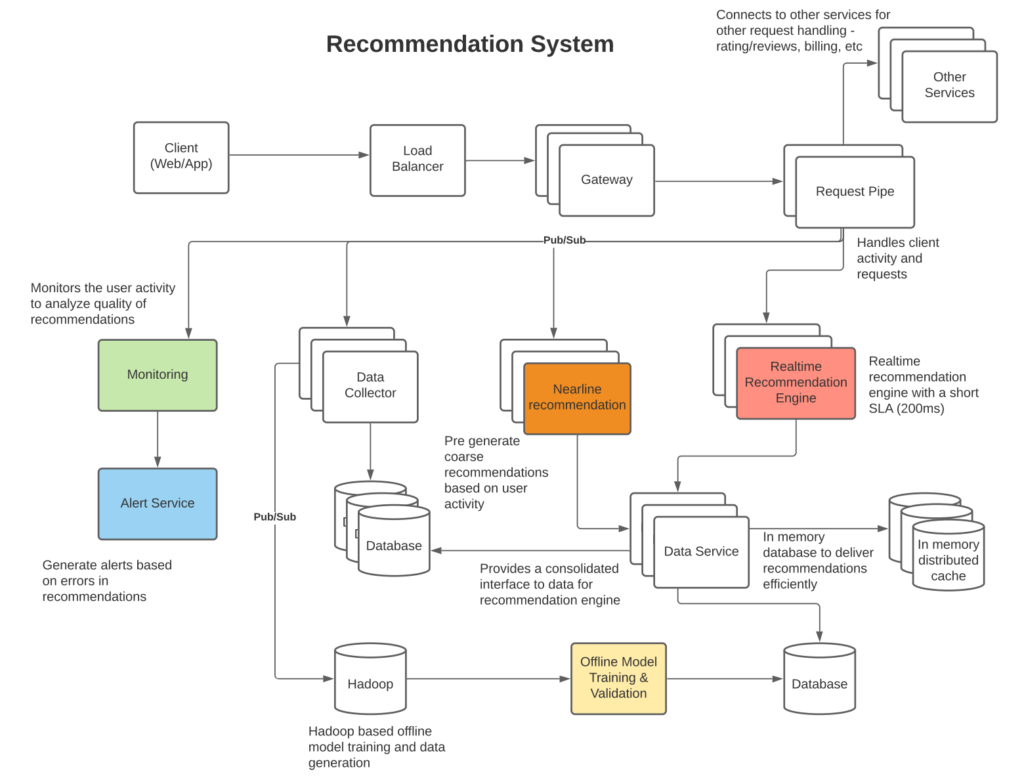
- High level architecture: Describes high level architecture of the recommendation system
- Recommendation Compute Levels: Describes various compute levels to manage a large scale efficiently
- Algorithms: Briefly describes few algorithms which are relevant in a recommendation system
- Data collection: Describes collection of user activity to feed into the recommendation engine
- Testing framework: Describes a framework to test recommendation algorithms so that new types of recommendations can be evaluated correctly before deployment
- Continuous monitoring: Describes need for continuous monitoring to evaluate errors in recommendation based on data (new users, items and interactions) so that algorithms can be adapted (model parameters tweaked or ensemble behavior adjusted) to resolve prediction errors
- References
High Level architecture
Recommendation Compute levels
Offline we can run batch compute to process similarities between users and items via various algorithms (more on the algorithms below). The offline compute can be designed to filter out of millions of items top 1K that apply to a certain category that the user is interested in – i.e., Top 10K “Computer Science Books” from millions of books that apply to user based on their past preferences.
Nearline as the user clicks on a computer science book on “Machine learning” we can asynchronously run an algorithm to pick top 100 ML books that apply to user preferences based on their current search pattern (i.e. in the current user session) and load them into a distributed in memory cache so as to provide fast lookups.
Realtime when user searches for a topic such as “Deep Learning”, we can use the in memory cache to pull 100 “Machine Learning” books and rank the top 25 “Deep Learning” books in Realtime. Since, we our operating on a small data set (100 books), we should be able to process the Top N quickly while ordering them on a score such as “purchase likelihood”. Assuming pulling data from an in memory cache takes 10 ms and then running a top N algorithm on a dataset consisting of a few hundred items takes 100ms, we should be able to return an ordered set of items to user in sub 200ms (near Realtime). This is fast enough response time for the user to have the impression that the system is responding in Realtime.
Algorithms
- Similarity: Recommendation systems need to implement concept of similarity that can provide a mechanism to compare how similar items are. A common method to determine similarity is “cosine similarity”, and it can be implemented as:

- (Eu (Ri – Ru) * (Rj – Ru)) / (SqRt (Eu (Ri^2)) * (SqRt (Eu (Rj^2))
- Eu = Sum over users
- Ri = Rating i
- Ru = Average rating of user u (so we can normalize the ratings)
- SqRt = Mathematical square root
- K-means clustering: Based on the user behavior such as movie ratings, users data can be segmented into K clusters. This is an unsupervised ML algorithm where the goal is to create K segments of data such that the overall distance of items from the closest center of segment is minimized. Clustering data enables us to locate other items in a cluster than can be used as recommendations to the user.
- Collaborative filtering: The idea behind collaborative filtering is to identify items via collaborative similarity. For example, via similarity of user choices that establishes user similarity, items that a similar user had rated or bought can be recommended to users. Item based similarity can be used similarly to find items similar to what the user has already bought or liked to find items that can be recommended to users.
- Content based filtering: The idea of content based filtering is to analyze data from the content and utilize that data to find similarity to other content.
- We can identify key words in the content via TF-IDF. And use that to find other content with a high concentration of the key words.
- TF(term, document) = 1 + log (word frequency in document)
- IDF(term) = log (total number of docs/ number of docs containing the term)
- We can link documents to topics via Latent Dirichlet allocations (LDA)
- LDA creates a set of probability-topic pairs that can used to link documents to topics and thus find other content that has a high concentration of the same topic.
- We can identify key words in the content via TF-IDF. And use that to find other content with a high concentration of the key words.
- Ensemble: Its likely that the system will get best results off of the recommendation framework if the framework is constructed as a set of hybrid recommendation engines which can combine efforts to construct the overall recommendations. Pipelines can be constructed such that based on various signals one recommendation engine can be preferred over another or an aggregate recommendation be made based on collective recommendations of various engines while assigning weights to recommendation engine outputs based on linear regression.
Data Collection
User events such as searches & clicks needs to be collected so that they can be added to the model training set. We can structure our data collection to be session based where the collective user activity in the current session is used during the Realtime recommendation generation to give more relevant data to users based on their current patterns. And in addition the activity should be published to a data collector where it can be stored into a persistent data store for the model to later use.
Testing framework
A crucial part of a recommendation system is that it will need to be constantly updated based on changing data and in search of continuous improvements. Thus to support non breaking changes in the recommendation engine a framework will need to be constructed that can evaluate quality of the changes as they are made.
- We will need to setup a framework where we can split the data into training and test sets such that as we make updates into our recommendation model, we can use the training data to train the model and test data to validate its quality.
- For validating the model we can use mean square error (MAE) or root mean square error (RMSE) to qualify the quality change in the recommendation engine.
- The above tests will enable us to get offline validation on the model, but we will also need online validation and for that we can use A/B testing where we can release the model to a subset of users and measure the online performance of the model before releasing it to a larger set of users.
- When releasing new ranking algorithms to production, the system should be designed to add versioning into the system such that if the error rate of new recommendations is high, the system can easily fall back on previously generated recommendations.
Continuous monitoring
Continuous monitoring of the recommendation infrastructure. Recommendation models are built and tested with a fixed data. However, as new user tastes and content is gathered the quality of the previously validated recommendation engine may change with new data and thus the quality of the recommendations needs to be continuously monitored so that we can tweak factors in the recommendation model if needed. We can monitor the system via RMSE (root mean square error) to determine the change in predicted vs observed recommendations and create alerts identifying issues when error threshold is violated.
References
https://www.amazon.com/Practical-Recommender-Systems-Kim-Falk/dp/1617292702
This is an easy read on how to build practical recommendation systems.
Deep Neural Networks for YouTube Recommendations
Netflix – Using Navigation to Improve Recommendations in Real-Time