Will cover the below items in this design:
- Requirements
- API
- Prevent over use or abuse
- Capacity planning
- Possible design options and tradeoffs
- Expired URLs cleanup
- High level design
- Short Url creation, update and delete requests
- Url redirection
- Database design
- Base 62 Hash Encoding Algorithm
Requirements:
- Functional Requirements
- Shorten a long URL into a short one.
- Should be possible to generate multiple short urls for the same long url.
- Pick a custom short url for a long url.
- Links will expire after a timeout period that can be user specified.
- Redirect traffic requests for a short URL to the original URL.
- Non Functional Requirements
- System should be highly available
- 99p request serve time for read requests should be under 20ms
- 99p request serve time for write requests should be under 100ms
- Should be able to serve 1,000 QPS write requests
- Should be able to serve 1,000,000 QPS read requests
API
The purpose of a URL shortener is to transform a long URL into a short URL. It will provide the ability to redirect a short URL request to the original long URL.
The requests can be served over a REST API.
CreateShortUrl: A POST request to construct a short URL.
Parameters:
sessionId: String representing the session id of the user that’s requesting for the session to be created.
originalLongUrl: String representing the original URL that needs to be shortened.
customShortUrl: An optional string representing the short URL.
expiryTime: An optional date representing when the short URL will expire.
Return: On success return the short URL. Otherwise, on failure return an error code.
String createShortURL(sessionId, originalLongUrl, customShortUrl=null, DateTime expiryTime=null)
UpdateShortUrl: A PUT request to update a short URL. Where the long URL pointed to by the short URL can be modified.
Parameters:
sessionId: String representing the session id of the user that’s requesting for the session to be created.
originalLongUrl: String representing the original URL that needs to be shortened.
customShortUrl: A string representing the short URL.
expiryTime: An optional date representing when the short URL will expire.
Return: On success return the short URL. Otherwise, on failure return an error code.
String updateShortURL(sessionId, originalLongUrl, customShortUrl, DateTime expiryTime=null)
DeleteShortUrl: A DELETE request to delete a given short URL.
Parameters:
sessionId: String representing the session id of the user that’s requesting for the session to be created.
shortUrl: A string representing the short URL.
Return: Return success or failure error code depending on whether the request was successful or otherwise.
void deleteShortURL(sessionId, shortUrl)
Prevent Over Use or Abuse
We can allocate to a user a certain maximum number of short URLs that they can create. User requests can be denied when the number of short URLs by a user increase beyond a certain threshold.
In addition, we can apply rate-limiting based on user session or id to prevent certain clients from abusing the service. See an article that I wrote on rate-limiting here.
Capacity Planning
The requirements state that we are expecting 1000 write requests and 1 million read requests per second.
How much data do we need?
- In one day we are generating 10^5 (1 million seconds per day) * 10^3 (1 K per second write requests) requests. This amounts to 10^8 requests per day. Lets estimate storage capacity for 3 years. 3 years amount to aproximately 1K days. Hence , we need to store 10^11 short URL entries. If we assume each URL entry in database occupies 1K bytes of storage, the amount of data we need to store over 3 years is 10^14 bytes of data. This amounts to 100TB of data. If we replicate the data 3x, our total storage need is 300TB.
How many app servers do we need?
- If we assume that each app server has 12 cores and each core can run 8 active threads then per server we can have ~100 active threads (this is a conservative estimate, depending on the type of work load (compute vs io) commodity servers can possibly run many more threads per server).
- Regarding read requests: Assuming that 99% of the requests can be served from in process memory cache. The time taken to process a read request would be ~5ms (conservative estimate). Hence, one thread can serve 200 requests per second. And thus one server (100 threads) can serve 2*10^4 requests per second. Since we are targeting to serve 2*10^6 (2 million) read requests per second, we will need 50 servers to serve read requests. However, this estimate assumes that servers are operating at 100% capacity. We should estimate servers to be on average operating at 1/3rd their maximum capacity inorder to handle peak loads and for an increaed life span of the hardware. Thus we should estimate 150 read servers to serve this load.
- Regarding write requests: Assuming each write requests takes 30 ms (write to a write back cache which persists asynch to db), we can serve 30 write requests per thread per second on a single server. Thus with a server that has 100 threads, we can can serve 3K write requests per second. This is a much smaller load than the read requests and can infact be served by a single server. However, for high availability and in order to decrease load on a single server we can add 3 servers to serve the write request.
How much in-process and distributed memory will we need?
- Assuming that we can serve read requests by 20% of the total storage space, we will need 20TB of memory. Commodity servers typically are available with memory as much as 126GB. Thus over 100 commodity servers we can store 12TB of data (this will be about 10% of total data). In addition, we can use a distributed in memory cache such as REDIS or MEMCACHED to store 20% of data (20 TB).
How many database servers will we need?
- Assuming each database server can store 1TB of data, we can have 100 DB instances to store 100 TB of data. In order to replicate the data 3x, we will need 300 DB servers.
- In order to enable fast db access from DB, we should allocate the primary database servers to have large memory (20% of storage capacity ~ 200GB). Databases use in memory buffers to speed up requests. Having a large in memory buffer will allow the database to be more efficient.
Possible Design Options And Trade-Offs
Counter-based approach: We can leverage a counter in a database that we increment per each short URL request. This will make our short URL design simple. However, since every write request is incrementing the same counter, and will run into a concurrency-related bottleneck in the DB. We could alleviate the database hits by batch allocating available counters into process memory (1K counters) and hit the database only when we run out of counters in the process memory. Another issue with this design is that the counter number will expose to users our usage patterns – i.e. users will be able to determine the rate of our short URL growth. We can circumvent this by rotating bits in the counter in a predefined manner. The counter will grow fairly large with usage. Hence, in order to keep the length of the short URL small, we can convert it to a higher base (i.e. base 62).
Hash-based approach: We can create an MD5 cryptographic hash of the long URL and take the first N characters from the hash to generate the short URL. However, we will run into collisions that we can handle by adding a unique id to the end of the short URL.
Pre-create available short URLs and feed them to the short URL creator: We can have a background process that pre-generates the short URLs and feeds them to short URL write processes over a queue. The background process can generate short URLs via a rotated counter which is converted to base 62. The advantage of this design is that short URL to long URL mapping can be done very efficiently since the short URL is pre-generated. We can also leverage this design to reuse previously expired short URLs.
We could also use an in process unique id generator (see snow flake unique ids here) to generate a 64 bit unique id and covert that to a base 62 string. This is a much simpler design. However, the 64 bit number can be very large and can potentially take up to 11 base 62 digits which maybe beyond the length of small URL that our requirements allow.
Expired URLs cleanup
Since the short URLs have an expiry time, we can have a batch process that runs once a day and deletes the expired short URLs from the database and in-process and distributed memory caches. These URLs can then be recycled for reuse.
High Level Design
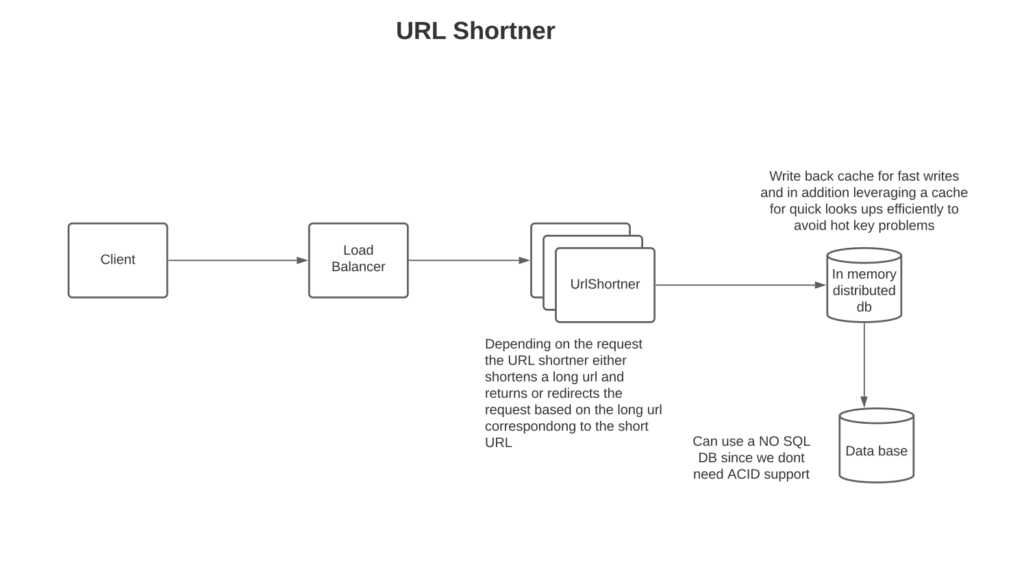
The url shortening requests will be processed as below:
Based on the type of request (create, update, delete), we perform the appropriate operation on the request. We return back a success or failure return code along with the data pertaining to the request – for example, the short URL for short URL creation requests.
The mapping is kept in an in-memory distributed cache for fast lookups. We use a write-back cache for fast writes since we don’t need strong consistency in our use case. See the article on caching strategies here in order to understand various caching strategies.
Url redirection
For URL redirecting, a request is picked up by the load balancer and directed to the appropriate server; the server loads the mapping from the in-memory cache if present; otherwise, it loads from DB and updates the in-memory cache before returning the request. The server returns the long URL to the client with HTTP 301 redirect. Could also return back to the client with 302 redirects. The difference between 301 and 302 redirects is that 301 is permanent and will result in reduced server traffic, whereas 302 is temporary, and thus client requests can be utilized for analytics.
Database storage:
The data can be stored in a database table that provides a mapping from long to short URL and vice versa.
| ShortUrl (PK) | LongUrl | UserID | ExpiryTime |
We are storing 100 billion rows in the database over a period of 3 years. This is a lot of data to hold in a single table in a single database. We can store the data in a NoSQL DB such as Cassandra where we can “shard” the data based on “ShortURL” (primary key). In addition, we can create indexes on user id and expiry time to quickly retrieve entries by the user or those that are expiring. However, since the data is sharded by ShortUrl, we will need to do a scatter-gather query to retrieve the count of short URLs by the user or a list of short URLs that are expiring.
We could also have stored the data in a relational database and sharded the data over a Short URL while managing the shard data distribution via a shard manager. In addition, we would have needed to set up replication.
Since we don’t need ACID compliance or cross-table constraints and given a NO-SQL setup such as Cassandra makes replication simpler to set up and maintain, NO-SQL would be a better choice for data storage here.
Base 62 encoding Algorithms
public class EncodeAndDecodeTinyUrl {
public static void main(String [] args) {
EncodeAndDecodeTinyUrl encode = new EncodeAndDecodeTinyUrl();
String url = "https://leetcode.com/problems/design-tinyurl";
String val = encode.encodeHash(url);
String url2 = encode.decodeHash(val);
System.out.println(url);
System.out.println(url2);
}
//count of the distinct url request
long count = 0;
//base62 char mappings
String chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";
//hash map for look ups
Map<String, String> map62 = new HashMap<>();
Map<String, String> mapHash = new HashMap<>();
/**
* uses the hash of the long url to encode a short string
*/
public String encodeHash(String longUrl) {
int hash = Math.abs(longUrl.hashCode());
StringBuilder origKey = new StringBuilder(convertBase10To62(hash));
String key = origKey.toString();
int offset = 0;
//if there is a conflict roll the key until you find a unique key
while (mapHash.containsKey(key)) {
if ((offset % 62) ==0) {
origKey.append("Z");
offset=0;
}
key = origKey.toString() + chars.charAt(offset);
offset++;
}
mapHash.put(key, longUrl);
return "http://tinyurl.com/" + key;
}
/**
* convert the short url to its equivalent long url
*/
public String decodeHash(String shortUrl) {
return mapHash.get(shortUrl.replace("http://tinyurl.com/", ""));
}
/**
* decode's the long url to equivalent short url
*/
public String encode62(String longUrl) {
String key = convertBase10To62(++count);
map62.put(key, longUrl);
return "http://tinyurl.com/" + key;
}
/**
* uses the mapping to return the equivalent long url
*/
public String decode62(String shortUrl) {
return map62.get(shortUrl.replace("http://tinyurl.com/", ""));
}
/**
* converts the val to base 62 string
*/
public String convertBase10To62(long val) {
StringBuilder sb = new StringBuilder();
while (val > 0) {
//find 62 bit based char corresponding to the current mod value
sb.append(chars.charAt((int) (val % 62)));
val /= 62; //divide the value by 62
}
return sb.toString();
}
}