- Requirements
- Document Parsing
- Inverted Indexes
- Query Parsing
- Search Retrieval Strategies
- Scaling Search
- Search frameworks
- Realtime Log Alert System
- References
Requirements
We will in this document cover at a high level how a search system is implemented.
Document Parsing
A document could be a webpage, word, PDF or any other document that contains a bag of words.
We can create a taxonomy on the document to identify its title, headings, opening paragraph, ending paragraph and other text so that we can create more specialized text searches.
Stream of words in the document are transformed as tokens where the tokens are :
- Cleaned : run spelling check to fix misspellings in the document
- Identify keywords: Keywords such as SanFrancisco are identified and left untouched by the stemming process so that searches on keywords correctly
- Stemming/Normalization:
- Normalize the words so that words that belong to the same root are treated similar (i.e. transform runs and running into run)
- Normalize on acronyms such that IBM, and I.B.M get treated as IBM.
- Transform capitalized words to lower case
- Synonyms: Add synonyms of the words together with the original word so that search documents containing synonyms can be included in the search classification.
- To save space, we can expand synonyms when parsing the query document rather than when parsing content documents.
- Stop words :
- We can choose to ignore stop words such as (an, it, the, etc) because these words occur often in a document and independently do not carry significance
- However, these words can carry significance together with words that follow them. Hence, we can save these words as “shingles” with the word that follows them (i.e. transom “the wall” into “the_wall” & “wall”).
Once the document has been parsed, we can run a classification algorithm to classify the document into a main and sub category. For example if the document contains a lot of programming words such as “streams in java”, the document could be classified as a “technology/java”. Classification can be done based on a set of rules or a machine learning algorithm or a combination of them.
Meta data can be added on the document to help in search engine’s ranking. For example, if the document contains information on search and is published as part of Stanford’s information retrieval course, it can have more weight in search retrieval vs if its published on a random site by an unknown author.
Inverted Indexes
An “inverted index” is a data structure which for each term contains a list of documents containing the term. A more sophisticated inverted index can have frequency of term per document along with their offset and position in the document stored as part of the inverted index. The frequency of the term in a document can be used in search ranking to identify more relevant documents. Offset of the term can be used to highlight the content in the document after the search and the position can be used in phrase queries to identify ordering and nearness of words.

Query Parsing
A query can be treated just as a document where the query is processed through the same document parsing and index construction machinery that regular documents are processed through. Once the query is processed the intention is to determine the intent of the query and apply a search retrieval strategies (indicated below) to retrieve documents that cater to the query.
Search Retrieval Strategies
Boolean search:
- This is a simplest form of search constructed by using a grammar consisting of AND, OR and NOT. Hence, a query such as “Star Trek” can be parsed into tokens “star trek” and then matched against movie titles containing the tokens “star” & “trek”.
- A more sophisticated form of the query can be of the form “star trek patrick stewart”. As part of query analysis, we can determine that the tokens “partick” and “stewart” are in fact people names. And then run a query that matches “star” & “trek” against movie titles and “patrick” & “stewart” against cast names.
- Behavior of the query can be adjusted by up/down boosting certain parameters, for example in the above query we can choose to give lower boost/preference to the title and hence more to cast names to pull in non Star Trek movies from Partick Stewart.
Term Vectors and Cosine Similarity
- For each term in one document
- We can capture in numerator a multiple of term’s weight in one document * term’s weight in second document
- And add the above
- Then divide the numerator by length of the first document and that of the second document to normalize the word weights over the document lengths
- Take the cosine of the value calculated above to determine the similarity between the two documents. Cosine value is inversely proportional to the angle between the two documents.
- The documents are divided by their lengths to normalize the frequency of words over the length of the document. This will allow long and short documents to be similarly treated as based on the frequency.

Clustering Queries
- We can correlate a query to a category based on similarity of the query to a category.
- And then search relevance on the documents in the given cluster than the universe of all documents to narrow down the search.
- See lectures 12 & 13 presentation in Stanford CS 276 to lear3n more about document classification.
Scaling search on a large document set
We can utilize a map reduce framework to map documents across nodes that individually parse and process the documents. And then reduce the mapped documents to a merged inverted index. See details in images below.
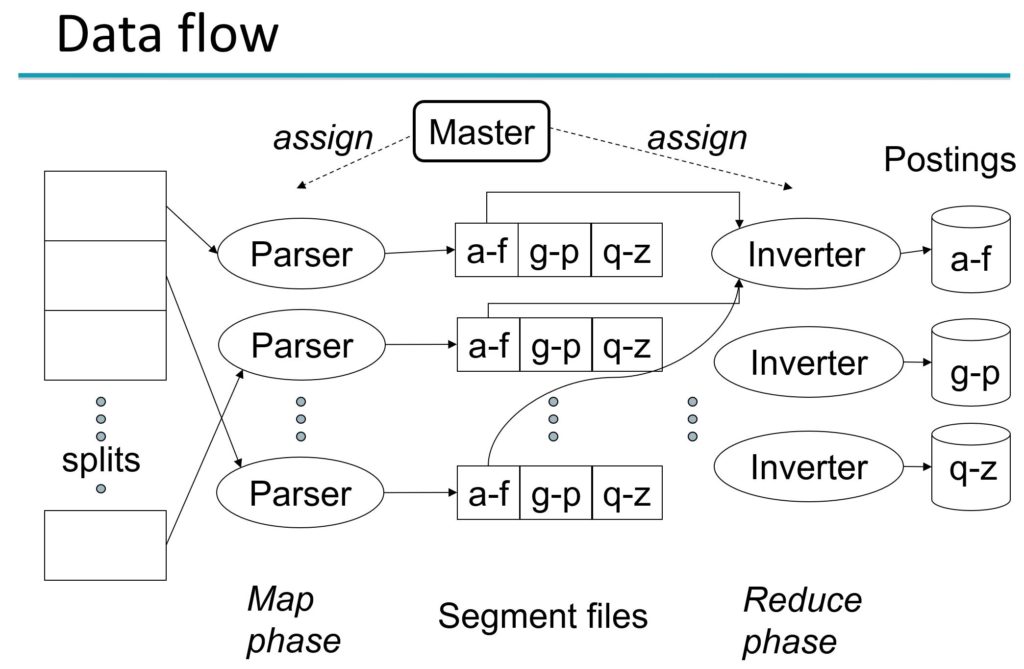
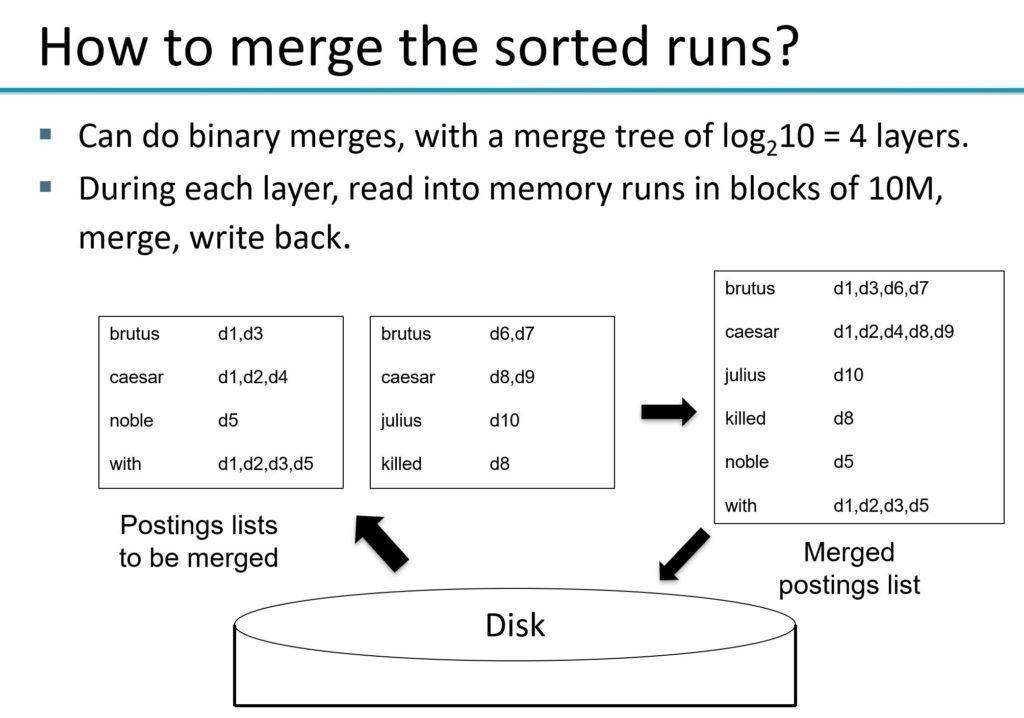
When processing queries we can spread the query across servers, each of which process a subset of documents. The work across servers can be combined together in the aggregator before returning the results back to the user. An alternative approach could be to partition the work across terms. Partitioning work across terms can be problematic as each server doesn’t have sufficient information across terms to give an overall rank to the document and thus the aggregator will have to do additional work once the individual terms are ranked. In addition, termed partitioned indexes wont be able to process phrase queries (consisting of multiple terms) correctly. Therefore, in order to improve time efficiency and result accuracy, document partitioned indexes are a better approach.
Search Frameworks
- Lucene is an excellent library that provides functionality to crea te inverted indexes on documents and then use various search criteria to process queries.
- Elastic Search & Solr are frameworks built on top of Lucene to facilitate search retrieval.
Realtime Log Alert System
Here I briefly describe a way to process queries on a streaming data such as logs. The use case could be to trigger alerts when a log line matches a query condition.
- In this system , its very likely that the number of documents (log lines) will be significantly larger than the number of queries.
- We could set up the stream of logs to be published over a queue such as Kafka. A queue is used here so that we can decouple search from clients that generate log. In addition, queue provides a buffer for logs during peak traffic when the log (document) ingestion rate is slower than the log generation rate.
- We can pre-index the user queries (generate an inverted index) and distribute the queries over a series of nodes via consistent hash. New queries can be similarly indexed against a node using consistent hash. The inverted index and any alerts/actions on queries can be saved into a key-value data store.
- A new log is picked up by a log worker, the worker parses the log and generate its inverted index, which we store on a write back cache (Redis) backed by a key value data store. We then publish the log id to each of the query nodes (see #3) over a pub-sub medium such as Kafka.
- Once a published log is received by a query node and for each query we do the following:
- Run a crude search to detect a possible match on the query and the log line. We are doing a crude search here to quickly bypass queries that don’t match the log lines. For example, if none of the tokens in the query matches the log, we can bypass the query. The reason to do a crude search is to avoid doing a more complex match if possible.
- For queries that have a possible match, we do a more detailed match to correctly identify a possible match condition. For example, if the query is “Service Moonshot time : time-value” and trigger when time-value > 1000, its likely that “Moonshot” is the most unique term in the query across documents and thus we can use “Moonshot” to identify a possible match. If the “Moonshot” match is successful, we can do a more detailed match and if successful, parse for “time-value” field in the query and use it to compare against the greater-than 1000 condition in the query.
- A query match can have an action registered against it, such as an alert or a task that is executed if a match is correctly made.
See here a high level diagram of the above:

References
https://web.stanford.edu/class/cs276/
Introduction to Information Retrieval
https://blog.insightdatascience.com/building-a-streaming-search-platform
https://www.confluent.io/blog/real-time-full-text-search-with-luwak-and-samza/