- Requirements: Describes requirements which we will cover in this design
- Storage and capacity: Describes storage and capacity needed to process the messages
- Client Login: Discusses actions that occur when a client logs in
- Sending a message: Describes the process of sending messages
- Managing client status: Discusses how the system manages the status of the client
- Cross-device synchronization: Discusses the process of synchronizing content across client devices
- See unread messages: Discusses details of how the client discovers new messages
- Load balancing: Discusses how the system balances the load
- Design choices to manage high system load: Discusses how the system manages high load
- Design choices to enable high performance: Discusses how the system enables high performance
- Services in the chat system: Discusses various services in the system
- Physical Database tables: Describes various physical database that the system will use
- In-memory database tables: Describes various in-memory database tables to enable high performance
- References
Here I am describing the design of a chat system that follows mostly the slack model. The functionality this system will support is:
- One to one chat in real-time
- Channel-based group chat in real-time
- Cross-device synchronization of messages
- Ability to see unread messages in channels
- The design will focus on low latency, high resiliency, and throughput.
- Lets consider the below requirements :
- Assume we have a 100 million total users.
- 50% of the users are active.
- Each users sends 100 messages daily.
- A single message is broadcasted to an average of 5 users due to group messaging.
- We need to keep messages stored for 5 years
Storage and capacity estimates
Storage space:
Per the storage table below, we can assume that each message occupies 500bytes of space. Given 50 million daily active users and each sending 100 messages, our daily message growth will be 50*10^6*100*500 (bytes) = 2.5TB. Thus the yearly data storage will be 900TB. Expanded over 5 years this amounts to about 5PB. Much of this data can be compressed, assuming a compression ratio of 70%, our compressed data will be less than 2PB.
We can keep one month of recent data in a non-compressed form which will amount to 70TB of space.
Distributed memory:
We can choose to store the following data in memory :
- Last 5 days of messages : 15TB
- User devices, active channels, activity, frequent interactions. Assuming 100 million users and 1K of space per user, this will amount to 100GB of space.
- Thus the total memory needed is aproximately 15TB. Assuming a single commodity machine can provide 128GB of space, this data can be stored across 200 servers
Application servers:
- We are estimating 50 million users sending 100 messages in a day. This amounts to 50K message writes per second. Assuming a commodity machine with 12 cores can run 1K threads and each write takes 50ms, a single thread can process 20 requests per second. Therefore a single machine can process 20K write messages per second. Assuming a machine is run at 25% of total capacity, this amounts to a single machine processing 5K write message per second. And thus 10 machines are needed to process 50K per second writes.
- Per these requirements, a message on average needs to be transmitted to 5 users, and assuming that each user has 3 devices, a single message would need to be sent to 15 devices. Thus we would need to service 1 million read requests per second. Assuming 1K threads and each read taking 10ms to process, a single thread can process 100 read requests in a second. And thus 1K threads can service 100K read requests at full capacity. Assuming a machine runs at 25% of maximum capacity, a machine should be able to service 25K read requests per second. Therefore, we will need aproximately 50 servers to process the read requests.
- Additionally users make other requests such as for channel creation, permission updates, profile changes. In addition, there is work that needs to be processed asynchronously, such as to update user status and transmit updated status to other users for which we will need additional compute.
Client login
The client has embedded within the client application a bookmark that indicates a timestamp when the client last received a message. The client after that requests new messages starting from the bookmark. This results in less data transmitted from the server to the client. Secondly, the service keeps track of channels in which the user actively participated ‘user_active_channels’. Thus, the service returns to the client only messages in the active channels, thereby reducing the amount of data sent to the client. Later if a client clicks on a channel that the client hasn’t participated in a long time, the client makes a call to the service to load recent messages in that channel. This is called lazy loading and the intention is to reduce the load on the server when the client logins. We will return back to the client the data in pages so that on any given request less data is transmitted.
Lastly, when a client logs in their status will become online, the change in status must be transmitted to the interested parties. Transmitting the change in client status to every user in the organization will take a lot of bandwidth; we can save the bandwidth taken by transmitting change in status to only those clients that the given client frequently interacts with. We can leverage the table user_frequent_interactions to get a list of users the user interacts with often and only publish the status change to that list of users.
Sending a message
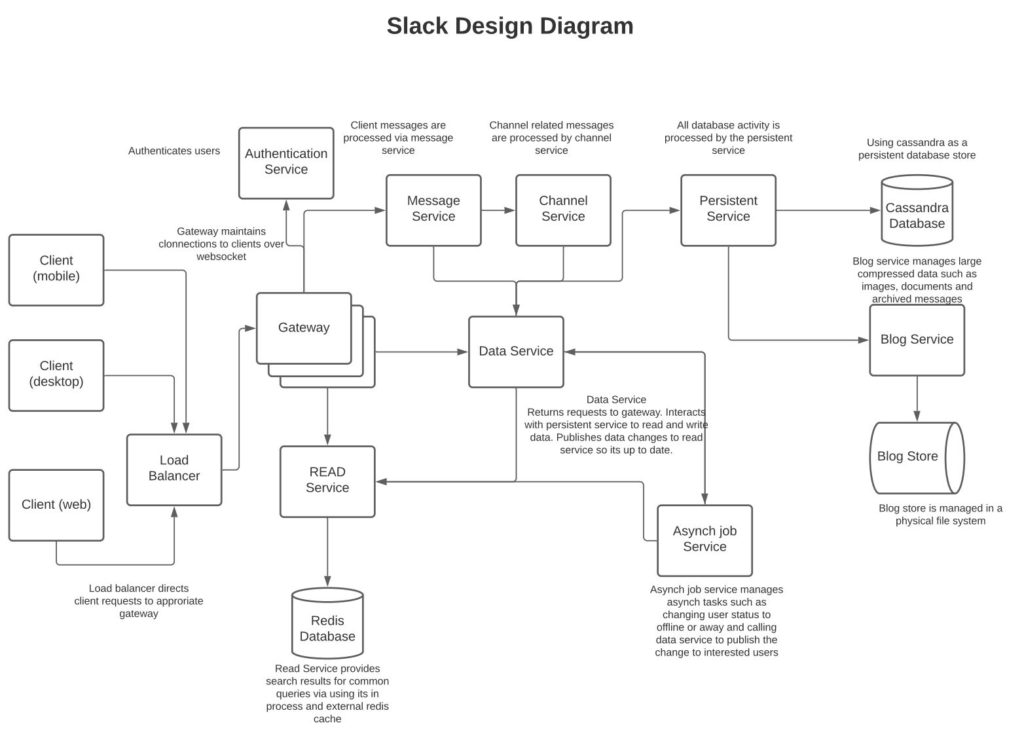
The client sends a direct message to a user or sends a message in a channel that has several users. This is handled by the client making a connection to the gateway and sending the data over WebSocket to the gateway. Alternatively, we could have used long polling on the client but that would prevent clients from receiving messages in near real-time. In addition, long polling will periodically make calls to the gateway that don’t return data and hence add unnecessary load on the backend. The gateway makes a call to the message service indicating the message content, the user who sent the message, and the channel it was sent. The messaging service passes the call to the data service, which calls persist service to persist the message and then publishes it to appropriate users. The reason to have the message pass through the message service is that the logic of handling various message types can live in the messaging service. For example, a message to create a new channel or add a user to a channel is picked by the messaging service and then passed to the channel service.
Managing client status
Client status such as when the client comes online goes offline or becomes inactive needs to be managed. This is done by leveraging the user_info table into which client information, such as the last time the client sent a message and when the heartbeat was last received from the client is stored. The async job service processes this data and can thus change the status of the user from online to away when the client hasn’t been recently active or from away to offline when the heartbeat hasn’t been received from a client in some time.
Cross device synchronization
User_device table contains the devices with which the client is currently connected. Via this table, when a client sends a message on one device, the other devices with which the user is connected get that message. When a client connects with a new device the user_device table gets a new entry indicating that the client connected from a device. Later heartbeat messages from the device are updated in this table. When the last time the heartbeat received from a client’s device fall behind a certain threshold, the async job service removes the device from the active device list.
See unread messages
New messages are transmitted to the client; the client has the logic to direct the message into the appropriate channel in UI. Therefore, the client can record the number of unread messages in a channel and thus display that number to the user. When a user reads the messages in any of the channels in one device, a message is sent to the gateway that the user has read messages in the channel. The gateway then sends a message to a notification service that synchronizes the read information across other devices that the client is connected with.
Load balancing
Load balancing can be done via a consistent hash so that a user consistently connects to the same gateway and the number of connected users across gateways is uniformly distributed. A client can connect to a gateway that is geographically closest to the client. In case the gateway at the specific data center is not the primary data center that manages the channel content, the client can be redirected to the gateway at a datacenter that is responsible to manage the channel data.
Other things of note
- Clients publish the heartbeat to the gateway, which updates the in-memory tables user_info and user_devices to mark the specified device as online or offline. When a user sends a message, the gateway checks whether the user’s status is active. If not active then it changes the user’s status to active. It also updates the last activity time in the user_info table.
- Background job checks the user_info and user_devices table. If a user device has no heartbeat in the last X minutes, it deletes the row for user and device. It also checks the user_info table and if the user has no activity in the last Y time, it marks the user as away. If there is no heartbeat from the user in the user_info table in the last Z minutes, it marks the user status as offline.
Design choices to manage high system load
- Prevent attacks via not allowing messages beyond a certain threshold per second from clients. Return error to client when number of messages exceed the threshold.
- At times when the load is exceptionally high disable certain services such as user status.
- Create a rate limiter which queues message in the async job service for async processing rather than real-time processing when the load is high.
Design choices to enable high performance
- The READ service should be designed to keep a large in-process cache backed by a distributed in-memory DB. The service can return search results quickly via decreasing load on the data service and DB. Services should utilize in-memory caches as much as possible rather than the physical database or external services.
- Design to enable lazy load on the client. The problem we’d run into is that every time a client opens it has a lot of data to fetch. For example, if the user is in 1000 channels and is logging in after a week, the user will bring a week of data in 1000 channels. A typical user is perhaps only active in less than ten channels and doesn’t need the data in all channels. We could keep a table in the distributed in memory db that indicates active channels for a user and then on start only load data for channels where the user is active.
- We should work based on bookmarks when a client connects. For example, a client already has data that was up to date at a given time. Therefore, the client only needs data after that time. Thus, the client can request to load data that changed only after the bookmark. This can be solved via loading data for channels where the user is active (user_active_channels) and searching in channels where the channel change time is greater than the bookmark time.
- Shard the data appropriately. This can be done by using keys that give reasonable data distribution and locality.
Rather than a monolith, we should design to distribute the work across many services rather than keeping bulk of logic in a single service as maintaining a large singular code base and monolithic services becomes difficult.
Services in the chat system
Gateway: Handles connections to clients over WebSocket. It’s a good idea to keep the client’s interface via one service where communication is WebSocket (client to server and vice versa) and then communicate between the gateway and other internal services over an in-house protocol that reduces network load.
READ Service: This can be used to cache most used data in memory and thus return fast results. The service should be designed to return quick search results. Updates to data in this service are made via data service over pub/sub, the gateway itself, or async job queue. For example, when a gateway receives a heartbeat it can update the heartbeat in the read service, similarly, when data service receives a message in a channel by a user it can publish to this service a message indicating that the user was active in a given channel. Similarly, when async job changes the status of a user, it can update that in the read service.
Message service: Processes messages from clients.
Channel service: This service can be used to process channel-related messages, such as channel creation, channel close, managing users in a channel, channel privacy, and such.
Data service: Returns requests to gateway service. Calls to persistent service to read and write data. Gateway service will call into this service to load the data when a client connects. Publishes data changes to read service so that read service stays up to date.
Persistent Service: Reads and writes the data to database and blog service. The idea is that rather than multiple services reading and writing data to the database directly, they go through the persistent service. Thus, query optimization and table changes can easily be managed as they will reside in a single service rather than spread across multiple services.
Blog service: Reads and writes data into blog storage. Images, archived messages, voice messages, and other large data can be saved here.
Archival service: A problem with persistent message stores is that over time the tables will grow very big and become non-performant. Typically, users only need recent data, but because of compliance reasons may need to store historical messages for an extended period. This can be achieved via converting old messages into a serialization format such as Avro, compressing the binary data, and storing it into the blob while keeping a URI to the location in the blob in the message table.
Asynch job service: Background requests such as managing user status, user interactions, active channels can be managed via this service.
Authentication service: Checks user entitlements to authenticate the login.
Physical Database: Any relational database could work but given Cassandra’s design that easily enables replication and managing high writes load, I think it will be a better choice over a relational model given we have created an in-memory READ service to provide fast reads.
In-memory database: An in-memory database such as Redis will greatly benefit performance as frequent search results can be answered via the in-memory data store than making a call to the physical database.
See the various database tables below:
user_info : serves queries for user information
Columns: user_id, user_name, user_role, user_description
organization_info : serves queries for the organization information
Columns: org_id, org_name, org_description
organization_users: returns list of users in an organization
Columns: org_id , user_id
channel_info: returns information about a channel
channel_id, org_id, channel_name, channel_description
channel_messages: returns messages in a given channel. If the message contains an image, the blob_url will contain a reference to the image in the blob. If the message has been compressed, is_compressed will be true and blob_url will indicate a link to the blob containing the message.
message_id, org_id, channel_id, user_id, sent_time, body, blob_url, is_compressed
channel_last_time : contains the last time the channel was updated
org_id, channel_id, last_time
user_active_channels : this table contains list of channels that the user is active in
org_id, user_id, channel_id, last_time
Below tables are contained in an in-memory DB such as Redis for quick access:
user_active_channels : this table is loaded into the distributed in-memory DB as there will be frequent load requests for this table.
user_activity: this table returns information such as the gateway to which the user is connected, the user’s last heartbeat, activity time, and status.
user_devices: this table stores the list of devices that a given user is connected with so that user messages can be synchronized across all devices
org_id, user_id, gateway_id, device_id, heart_beat_time
user_frequent_interactions: this table stores frequent interactions between users. And is leveraged to publish a user’s status to only a subset of users that the given user frequently interacts with rather than the whole firm. The pair user_id_1, user_id_2 can be stored in lexicographical order so that the information isn’t repeated.
org_id, user_id_1, user_id_2, last_time
HOW TO HANDLE THIS DESIGN QUESTION IN AN INTERVIEW
I would first ask the interviewer what areas in design I should cover, I would then sketch out a quick high-level design of the data pipes based on the areas that the interviewer wants to be covered while keeping a pipe to other areas but not expanding on them. Once the high-level design is laid, I will further ask the interviewer for feedback on what areas to go deeper in and focus on those areas. There is a lot of material to cover in the complete design and given the interview is likely around 30-45 mins, we will not have enough time to explain everything in detail.
https://blog.discord.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7