This article describes the design of news feed publishing services such as that provided by Facebook.
- Requirements
- API Design
- Capacity planning
- Newsfeed publishing
- Newsfeed retrieval
- Celebrities & Push vs Pull
- In memory caches
- Database Tables
- References
Requirements:
- Here we will implement a system where users can post some data in the system (text, image, video)
- Once the user posts the data, information regarding the data will become available on the user’s friends’ pages
- The order in which news feed data will appear in the pages will be determined by a ranking system
- The design will assume that a user can have a max of 5000 friends
- The design will assume 100 million daily users and a total of 1 billion users
- The data posted can contain text, pictures, and video
- Will not support functionality to enable permissions on who can view posts
- We will briefly look into how the system can be enhanced to provide cross-region support
A note: I have worked on financial systems where market data events trigger updates in systems to position the portfolio automatically (buy and sell items) based on the changing market conditions. The news feed system is very similar to how a user action (a post) changes the world view of a news feed for multiple users. Can correlate a post to a market data event and user’s news feed to a portfolio’s balanced positions. It’s fascinating how similar these concepts are under the hood.
From the user’s point of view, the system has two main parts, one the ability to make posts and the other ability to load news feed.
API Design
Get request to retrieve posts is set to return posts after a timestamp-based offset such that newer posts can be returned back to the client. The client will internally rank the posts based on new posts retrieved. The client will also use pagination to retrieve the posts:
GET /posts/{user_id}?offset=21&pagesize=10
(return 10 posts after the specified offset)
POST /posts/{user_id}
(create a new post)
DELETE /posts/{user_id}/{post_id}
(delete a specified post)
JSON post reply format :
posts [
{id, type, content, thumbnail, likes, [{comments}]}
]
The post reply can consist of an array of posts where each post contains the type of the post such as text, image, etc. Based on the post type the content can either contain text or link to a URI from which the content can be downloaded (i.e. for images or videos). The post can also include the first few comments on post. More comments can be retrieved based on pagination and user selection. Each comment consists of an object that contains the post content, user_id of the user who made the comment, and any other details regarding the comment such as the number of likes on the comment.
Capacity Planning
- App Tier:
- Writes : Assuming 1 billion daily pictures (each active user publishing 10 pictures daily), it amounts to 10K writes per second. Each write will amount into:
- Creating a URL record in database. Assume each meta data write record takes 50ms, a single core server can process at peak rate 20 requests per second. Given a typical commodity machine can be setup with 12 cores and 8 threads per core, we can have ~96 concurrent threads on a server. This amounts to 20*100=2K write requests per server at full capacity. If we allocate each server to operate at 25% of maximum capacity, it amounts to 500 requests per server. Thus 10K metadata write requests per second will take 20 servers to process.
- If we estimate a server takes 100ms to write into blob storage a single picture then by above estimates, we will need 40 servers to process 50K write requests.
- Assuming each active user loads 1K pictures daily, it amounts to 10^11 daily read requests.
- Assuming we are fetching the pictures from CDN and each picture load takes 50ms. This amounts to aproximately 10^6 per second requests ( 10^11/10^5) and assuming 50 MS to load picture , a single thread can process 20 picture requests per second. Thus a server with 100 concurrent threads can process 2K read requests per second at full capacity. If we estimate a server running at 25% of maximum capacity this amounts to 500 requests per second. Therefore, we will need (10^6/10^3)*2 = 2K servers.
- Writes : Assuming 1 billion daily pictures (each active user publishing 10 pictures daily), it amounts to 10K writes per second. Each write will amount into:
- Cache Tier
- Our daily number of pictures is 1 billion (10^9) and assuming we are caching the meta data information of these pictures in memory, it amounts to 10^9*10^2 =10^11 of space. Lets assume we want to cahce 25% of 3 months of pictures in memory, it will amount to 3*0.25*30*10^11 ~= 2.5TB of space. Assuming a single cache server can manage 128Gb of space , we will need 20 servers to cache this data.
- Database Storage Tier:
- Assuming we are planning capacity for 3 years and assume 10 pictures per active user daily, it means we are saving 1 billion pictures per day (100 million daily active users). Assuming each picture is 2KB in size, this amounts to 2TB of space daily. Over 3 years we have roughly 1000 days, so we need 2PB of space for storage.
- Assuming each meta data record consists of 200 bytes of space (user_id, photo_id, title, pictureUrl, thumbNailUrl, timeStamp, geoLocation, numberOfLikes, numberOfComments), we will need 5*10^9*10^3=10^15=1PB of storage.
Newsfeed Publishing:
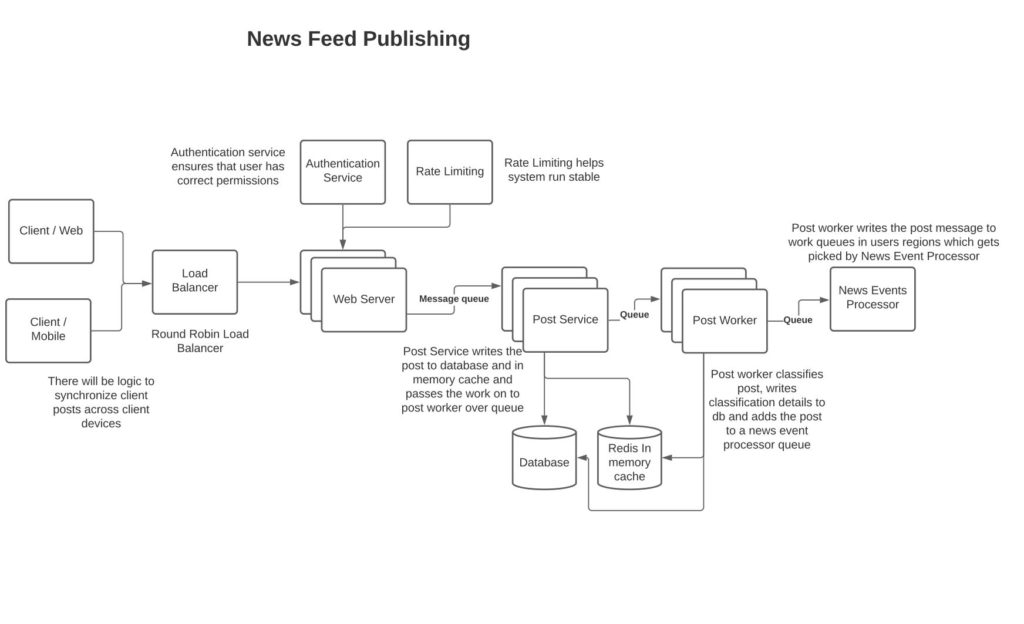
Post-construction:
Here the user making the post connects to a web server via a load balancer. The load balancer could be round-robin because the publishing node doesn’t need to be sticky for the user. The web server authenticates the user and applies rate limiting to enable a stable system load. The web server doesn’t write the post to DB but sends it over queue to the post service.
Post service:
Creates signed URL metadata and records the signed URL into the database. The signed URL is returned back to the client which uploads the photograph onto the signed URL.
Post worker:
This service analyzes the post to classify it based on various attributes so that it can later be ranked appropriately by the ranking service. It then retrieves friends of the user with high affinity and classifies friends by region. For each region, it posts a message to the news feed service identifying the post and list of users whose news feed needs to be updated based on the post. The reason to look at user affinity when processing the post is to not overwhelm the infrastructure with a high load. We can for example track the monthly active users and only push new post feeds to those users, for the rest of the users their newsfeed can be updated on demand.
Retrieving Newsfeed:
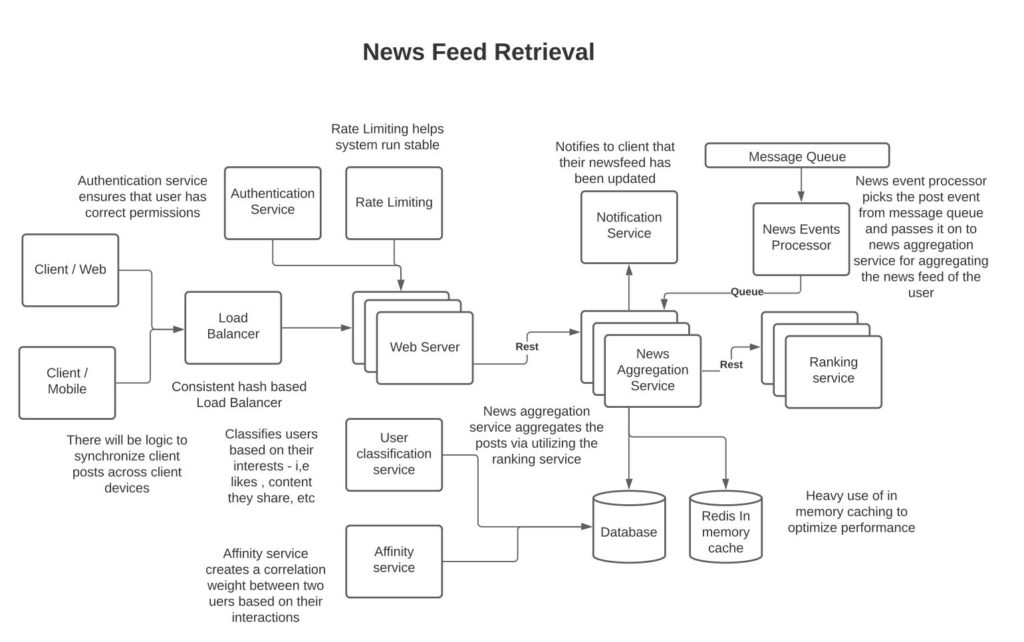
As discussed previously, the post-worker writes the message to a set of queues per region indicating a list of users whose news feed needs to be updated based on the post.
Newsfeed events processor:
These are a series of services that have subscribed to post messages. The service will pick up the post message and pass it on to a news aggregator service that manages the posts for a given user for each of the users on the message.
News aggregator service:
The news aggregator service is responsible for aggregating users’ newsfeeds. It retrieves the post message from a queue and works on updating the news feed of the user based on the updated post. It talks to a ranking service, which filters the posts that constitute the feed for a given user. The service then writes the posts comprising the user feed to the in-memory news feed cache so later news feed queries can be fetched quickly. The client can further enrich the data by requesting pictures and videos from CDNs using the URIs. An important note in the design of the news aggregator service is that we want to limit the amount of data that travels between the news aggregator service and the client UI to reduce the load on the network. This can be done by the client passing a time-based identifier with the request so that aggregator service sends news feed to the client as deltas – I,e new posts that the client hasn’t yet seen and that rank higher than the posts the client is already viewing. See in references an article by Facebook regarding distributing ranking work between client and server to improve client experience over slow networks.
Ranking service:
Given a list of posts constituting a news feed, the ranking service can filter and rank them in order. The filter is applied by the ranking service to remove posts that are under a certain threshold. See the excellent article by facebook below on how they utilize ML to rank news feeds. It can use a combination of the below to create the rank:
- Current user and post originating user affinity
- ML-based correlation between the user receiving the feed and content classified in the post by the post worker
- Timestamp of the post; recent posts can be given higher priority
- Feed from an ad service as a parameter driving the rank
Notification to clients of a newsfeed update:
A user is connected to the webserver over WebSocket via which the user can receive a notification event that the user’s newsfeed has an update. The user can then add a random weight over a range of milliseconds (500 – 5000) to wait before querying the newsfeed service for updated posts. The motivation for a random weight here is to distribute the workload on the infrastructure and avoid load spikes.
Client side ranking of news feeds:
When the user makes a request to the newsfeed service for new posts, it passes to the feed service a time-based identifier indicating the timestamp after which the user is interested in new posts. The feed service only returns back to the UI new posts, which rank higher than the posts client already has in its cache. The client would then merge the new posts into its cache and rerank the posts to give the user an updated news feed. See an article in references below by Facebook explaining client-side ranking in more detail.
Affinity service:
This runs periodically to update affinity between friends based on how active a user is in responding to posts from another user via comments and actions such as likes.
User Classification service:
This service runs periodically to analyze recent user activities. Based on user likes, shares, etc., classifies user preferences so that the ranking service can rank posts appropriately based on user interests.
Celebrities & Pull vs Push Model
Pull model: We can create a pull model where news feeds are sent to clients based on client requests. This would create less load on the system especially when following celebrities. However, the system would not be near real-time based on pull spacing. In addition, some pull requests will return in no data.
Push model: To make the system more near real-time, we can create a push-based approach where users are sent news feeds immediately after they are created. However, as seen in this design the model creates more load on the system and especially so when celebrities publish a post since they have many followers.
To give users news feeds as soon as they become available so that users stay engaged with the platform, we can lean towards a push model but segregate users into categories such as “frequent users” and only publish news feeds to users who are frequently logged onto the platform in order to limit the load on the system. Other users can be fed feeds on a per request basis. Users who infrequently log in to the system can be sent feeds via an email based on batch processing.
In-memory caches:
Correctly constructed and utilized in-memory caches are critical for system efficiency. The following data should be considered for in-memory caching:
- Newsfeed cache – user id, post id, sequence id (can use Redis sorted set).
- Social graph – an in-memory structure representing the user relationships. Could be in form of user and list of friends.
- Counters – how often a post has likes, replies
- Content – it maybe that some content such as videos, images, etc are often referenced in post. Such content can be cached in memory.
Tables:
The tables can be sharded via consistent hash over user id to ensure that the information of the same user lives on the same shard. Consistent hash because it distributes data evenly across nodes and enables moving data between shards due to the addition or removal of nodes more efficiently.
Post
| User_id | Post_Id | Text | Blob_url | Timestamp |
The table contains information about user posts
Friends relationship
| User_id | Friend_id | Correlation_weight | Timestamp |
The table links a person to another person as a friend and assigns a correlation weight that the ranking system maintains and is used in aggregating posts inside the news feed.
Comment
| User_id | Comment_id | Text | Blob_url | Timestamp |
The table contains comment information
Post_to_comments
| UserId | Post_id | Comment_id | Sequence_Id |
Associates posts with comments
Activity
| UserId | ActivityId | CommentId | PostId | ActivityType | Timestamp |
References:
A good presentation on how to design a newsfeed
Some slides on how Etsy feed architecture works.
An article explaining criteria in the construction of facebook’s news feed.
https://www.facebook.com/help/1155510281178725/how-news-feed-works
An excellent article by facebook explaining how they use ML in ranking posts.
Another excellent article by Facebook on how they utilize ranking of feed on the client-side to improve user experience over slow network pipes.