Various simpler design problems are explained below. A common trend across these problems is that Kafka is used as a pipe. Data management is sharded. The shard key is carefully chosen so that similar events where possible are kept inside the same shard. This makes local data aggregation simpler. Where appropriate an in-memory cache is used for fast read queries. And data is persisted in a persistent store.
Monitoring System
This system processes and aggregates metrics while tracking a real time aggregate count of metrics which it feeds into a monitoring UI.

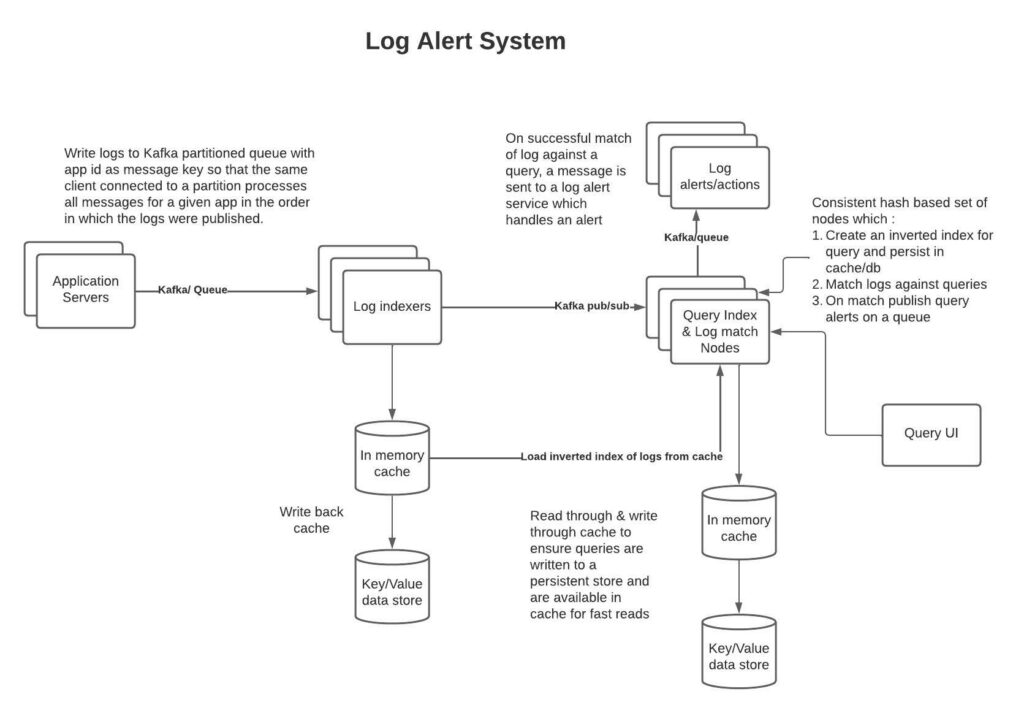
Log Alert System
The system tracks logs and creates alerts when the logs match successfully against queries.
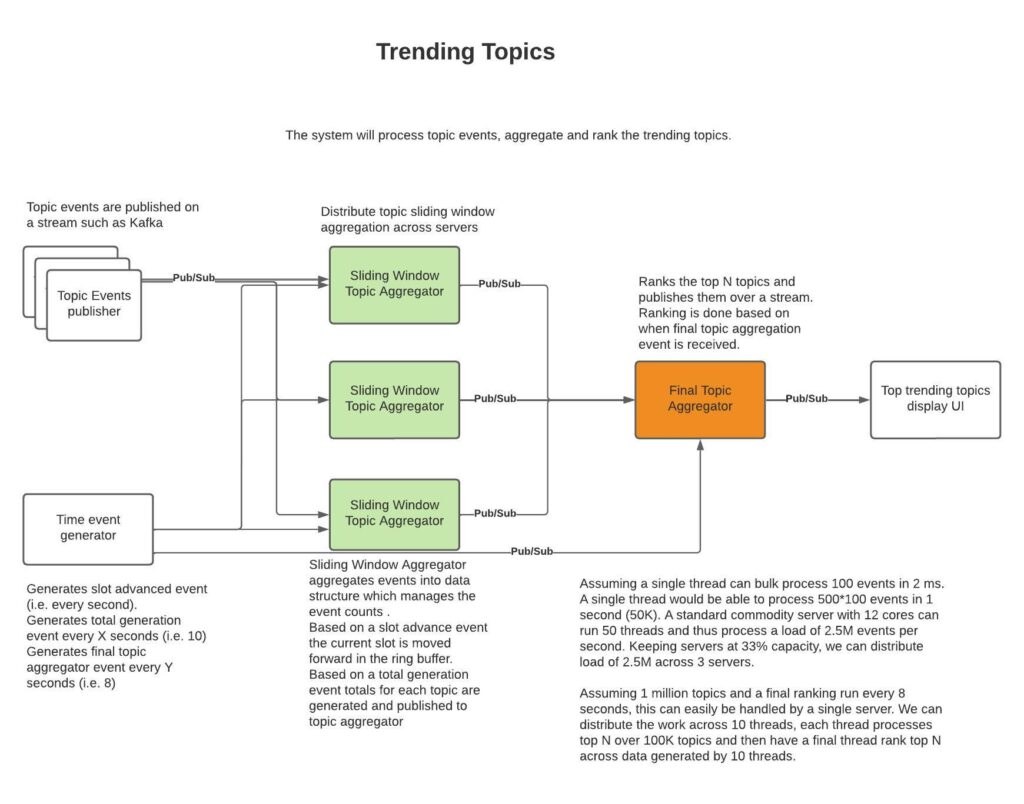
Trending Topics
Billionth Car
Here is a system to track the billionth event in a distributed data pipeline. What is interesting in this design is that there are local aggregators per shard and then a global aggregator across shards. A catch is that users may edit events within a time frame. This can be remedied by recalculating the billionth event after a prescribed delay once the billionth event is triggered.

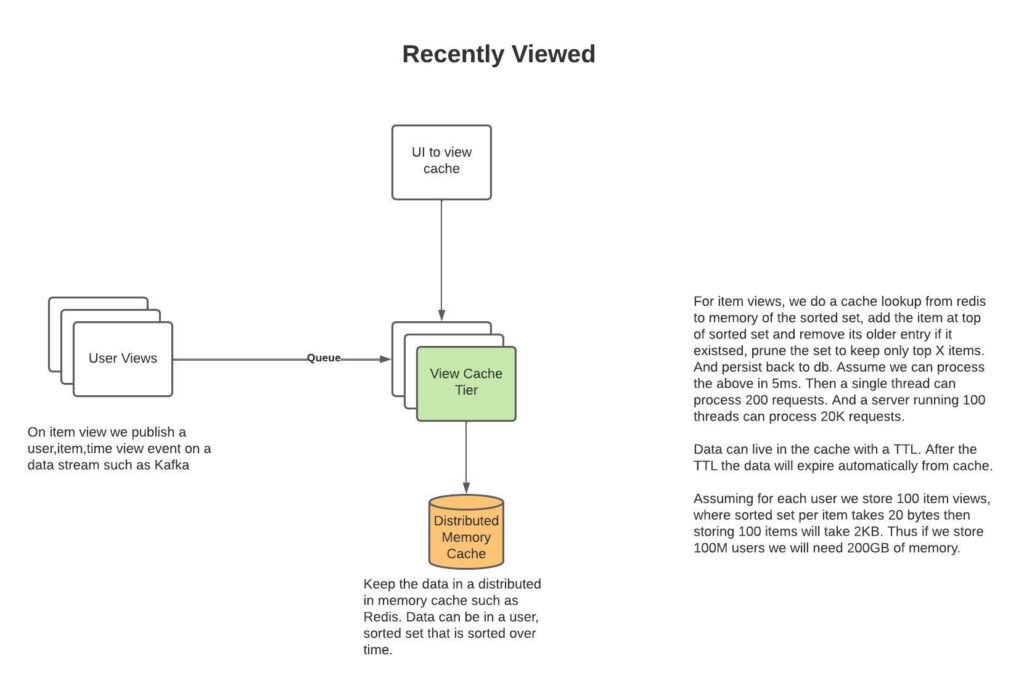
Recently Viewed
Below is a design to manage recently viewed cache efficiently via leveraging Redis.
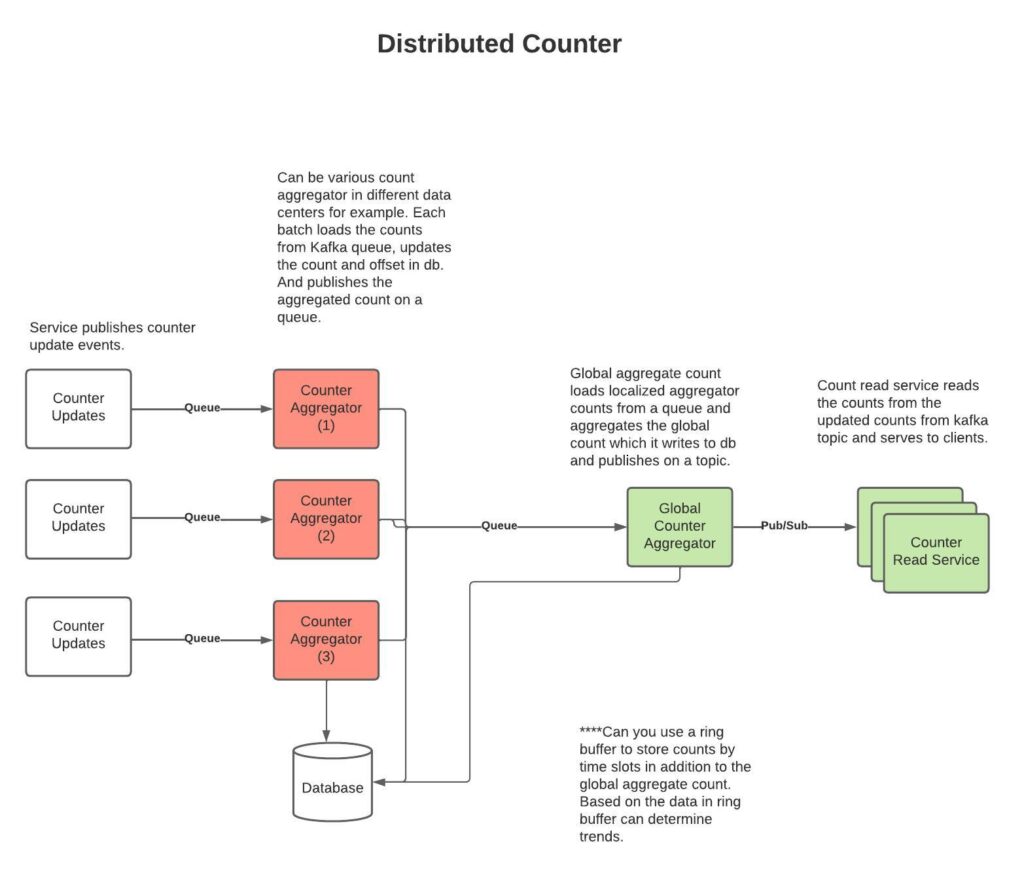
Distributed Counter
Here is a design of a system to maintain a distributed counter.