In this article, I am describing how to design a ticket master service. This service is attractive in that it requires strong consistency guarantees while issuing bookings. I tell here how we can leverage a distributed in-memory cache to provide large scale for view requests but manage the transactions physically in a relational database to ensure data consistency.
Content:
Requirements: Describe here the requirements considered in this design.
Storage and capacity estimation: Provide here back-of-envelope capacity estimation.
Ticket Master API: Lists the ticket master API
High-level design: Provide here a high-level overview of the design.
Movie or show search: Provide here information related to searching for movies.
Show reservation: Provide here information on show reservation.
Reservation wait queue: Provide here information related to the reservation wait queue.
Why use distributed in-memory cache: Describe reasoning for choosing to use a distributed in-memory cache.
Asynch process to clear lingering reservations and wait-queue entries: Describes various async techniques to keep reservations and wait-queues up to date.
Payment processing: Describes steps that should be taken to avoid erroneous payment.
Database schema: Describes the main database tables.
Database partitioning and replication: Describes how to shard the data to provide resiliency and scale and manage primary and secondary databases to provide consistent data for writes but enable fast reads via replicated data.
References: Indicates various references that I used while coming up with this design.
Users should be able to search for content, reserve various shows, and if shows are at full capacity, the user could be added to a waiting queue.
Search should be available based on genre, movie, location, cinema, or a combination of these parameters.
Per transaction, users should be able to book one or more seats.
The system should ensure that the same seats are not over-allocated – the same seat should not sold to more than one user.
The system should provide a consistent view of data to users. It should be resilient.
Storage and capacity estimation
There are around 20,000 cities in the USA. Let’s assume that 20% of those cities have cinemas or booking venues and that each city has on average ten booking venues. Let’s consider that each booking venue has five theatres. Finally, let’s assume that each theatre has an average capacity of 50 folks.
With the above gives the total number of cities are: 4,000
Thus the total number of booking venues or theaters is: 4K * 5 = 20k.
With a capacity of 50 folks per theater, this gives the total cinema capacity across the US as 200k.
Let’s assume that an average cinema runs five shows per day. This gives us the total maximum daily sales as 1m.
If we assume that an average cinema runs at 20% of its max sales capacity, then daily average sales are 200k.
Spread across the year, this amounts to a yearly sales of 73 million.
If we assume that the storage per sale requires 1KB of space, this amounts to 73GB of disk space per year.
Anticipated daily sales are at 200k. If we assume the number of daily views to be 100 times greater than the actual daily sales, then the total daily views amount to 20m. This amounts to 200 views or purchases per second. If we assume that the peak rate is 5x the average, we have 1K requests per second at max. Assuming a single database read returns in 100ms, we can per thread run 10 reads per second. A commodity machine with 12 cores can run 100 concurrent threads, so a single machine should be able to process this load. We can add redundancy by creating 3 servers dedicated to the read traffic.
Given daily sales of 200K, it amounts to 2 write requests per second. A single server can handle this request. However, to add redundancy we can share the read and write traffic in the same process and increase the read/write servers to 5 for added redundancy.
Movie bookings will require transactional consistency (ACID) in the database and thus we will need to utilize a relational database. We can set up the database in Active/Passive set up so that the passive database can take on the Active role if the active crashes. To isolate the reads from the writes, we can replicate the primary database to 3 read-only replicated instances and dedicate read traffic on those instances. Given our read load is 1K requests per second, we can set up our database to have a large memory so that the database can return most queries from memory than disk. Since we have 20K daily booking venues, running 5 shows a day, with a capacity of 50 folks per venue, our total daily maximum capacity is 20K*5*50 = 5m. Assuming each seat requires 1K of memory space in DB (conservative estimate), we will require 5GB of memory for 1 day of storage. Even if we estimate to cache 7 days of storage it can fit in 35GB of space. Thus we can run database servers with 64GB of memory space to serve our read requests.
Assuming each read query takes 100ms and assuming then a single database thread can process 10 read requests per second. Assuming our database is running on a machine with a large number of cores 24, we can run 100 threads per database server. Thus a single database server should be able to process 1K parallel read requests and having 3 database servers will provide added redundancy.
If we assume that there are 500 movies actively playing in any season, we can cache movie-related information such as reviews and trailers in a distributed cache. If we assume that memory needed to store information per movie is 50MB, then to cache data for 500 movies, we will need 25GB of space. 25GB can easily fit in a single distributed cache. To add redundancy, we can distribute the data across 3 distributed caches.
- Movie Search
- Search for a movie based on a series of filters such as: location, type, actor, date, theater
- GET /search?location=2138&radius=5&movieName=”Lord Of The Rings”
- Response would be in JSON form:
- [
- {
- “MovieID”: 1,
- “ShowID”: 1,
- “Title”: “Lord of The Rings”,
- “Description”: “Epic Fantasy”,
- “Duration”: 180,
- “Genre”: “Adventure”,
- …
- “Seats”:
- [
- {
- “Type”: “Regular”
- “Price”: 10.00
- “Status: “Almost Full”
- },
- {
- “Type”: “Premium”
- “Price”: 15.00
- “Status: “Available”
- }
- ]
- },
- Reserve Movie
- POST /reserve/{show_id}/seats=1,2,3
- PayForReservation
- POST /payments/{reservation_id}/details?cc_card=
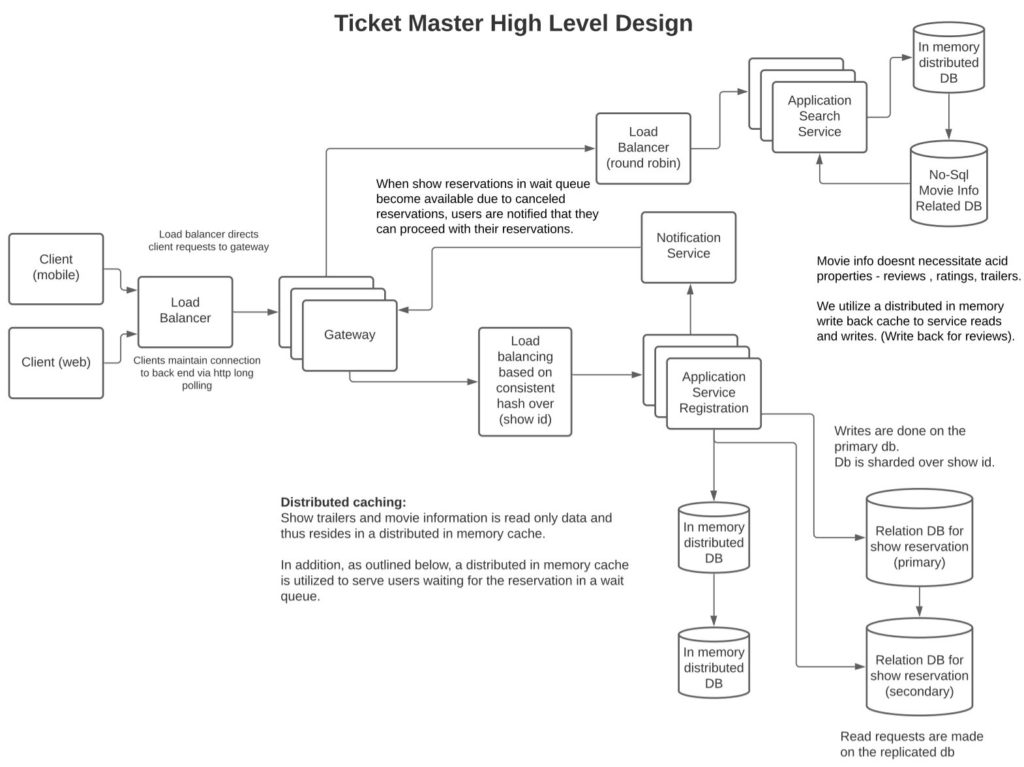
Based on the above usage, we can use a sharded (over show id) relational DB to manage ticketing integrity consistently. Furthermore, given we have a lot of read-only searches and views, we can serve them efficiently via utilizing a distributed in-memory cache. And in addition, store in-process memory booking information for shows in the coming week.
For payments, we can use a third-party platform such as stripe. We will need to prevent double charges and extra load on the payment platform by avoiding duplicate calls for the same transaction.
For ticket reservations, we will need to give users a time window during which they will need to complete the transaction or otherwise lose the reservation.
We will need to engineer a wait and notify mechanism to add users to a wait queue where they are served on a first-come, first-serve basis when seats become available.
To find places (theaters) based on geolocation, we can use a data structure such as a Region Quad-Tree. See more on quadtrees here.
A Quad region tree is a data structure where a quadtree node represents a geographic location, and the node contains one of:
– Set of places in that region
– Four pointers to other child nodes. When the number of places included in a quadtree node reaches a threshold (say 1,000), the tree can be divided into four children, each containing 250 places in this case.
The leaf nodes in a quadtree will contain the physical places, and the rest will contain pointers to their children. See the image below representing the quadtree.
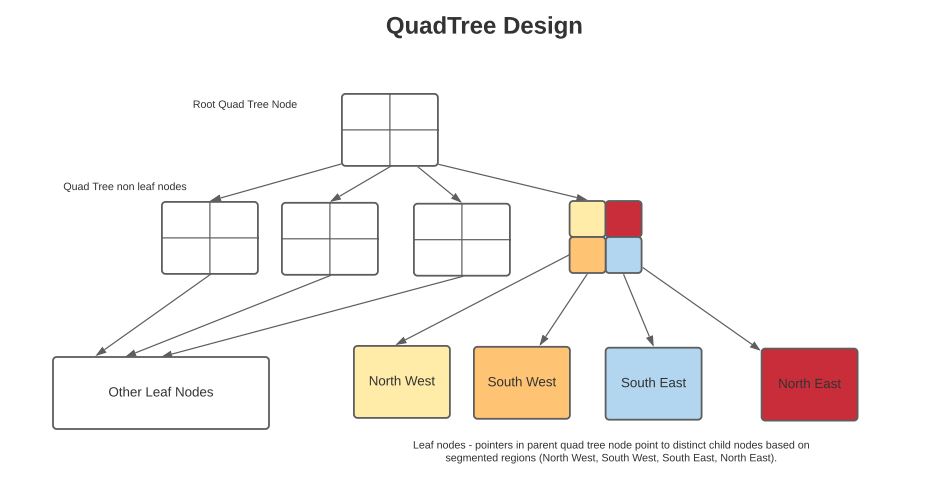
Thus, we can start with the complete area being considered (i.e., North America) as the root of the quadtree and, in our case, add theater locations to the quadtree. When the number of theaters in a node increase beyond our threshold of 1,000, we split the node into four children and so on until all theaters are saved into the quadtree.
This type of data structure is reasonably efficient in finding the places in a specific region as traversing down a tree is a log (N) operation. We can also find neighboring areas efficiently by allowing leaf quadtree nodes to have pointers to adjacent leaf nodes. Assuming each leaf node has 1K entries then a tree storing 100M places will have a height of 100*(10^6) / 1^3=100*10^3 = 10^5 leaf nodes. Assuming internal nodes are 1/3rd that of leaf nodes, we get the height of a tree storing large number of places as very small log 4 (10^5*1.3) ~= 9 (small height).
Calculating space that the Quad-Tree data structure will use:
Intermediate nodes will contain four pointers to quadtree and variables representing the location of the region. Therefore, the intermediate pointer nodes will need 4*8 (for each pointer to child nodes) + 8 (location id) = 40 bytes of space. Given internal nodes are 1/3 of the leaf nodes, they will take 100m/1000*1/3*40 = 1.33MB. Each time a new internal node is added the number of leaves decreases by 1 (one leaf becomes internal) and 4 new leaves are added. Hence, each transformation of internal to leaf adds (4-1) leaf nodes. Assuming N such transformations (internal nodes), the number of leaves = 3N.
On the leaf nodes, if we store a set of “places,” location id, and pointers to neighboring nodes, and we set up a leaf node to contain 1000 place ids. The size of a leaf node would be: 1000*64 (for place id and some metadata for the place) + 8 (latitude) + 8 (longitude) + 8 (left neighbor pointer ) + 8 (right neighbor pointer) = 64032 bytes. Thus, for storing 100 million places, we will need around 6.5GB of space.
Thus, the total space needed to represent the quadtree containing 100m places can easily fit into a single process memory since its around 6.5GB.
A quadtree data structure representing locations doesn’t fit very well for use cases where places in a particular area are constantly updating – such as a set of Uber drivers in a downtown location. This is because finding a place in the tree, removing it from a tree node, and adding to another tree node is an O(log(N)) operation instead of O (1). For such use cases where frequent updates to places are required, we rely on a geo hash-based library such as Google S2. See more on the S2 library in the design of uber here.
In use cases where the frequency of updates isn’t very high, we can reconstruct the quadtree periodically based on new data and replace the new tree with the old.
Another point to consider is that quadtree isn’t suitable for use cases where the number of places to be stored is enormous – over 1 billion – such a quadtree will be too big to manage in single process memory. In such use cases, we can use a hash-ring-based implementation over Google-S2, such as Uber’s one.
- A reservation server receives a request to reserve a set of seats in a show. The server makes a call to a stored proc in the database, which :
- A booking record identifying the transaction is created in DB.
- Starts a serialiable transaction.
- Checks that the seats being reserved are all indeed available. If any of them are not available, return false.
- If available, modify the status of seats to reserved.
- Update the status of booking to “Reservation-In-Progress”.
- If the reservation is successful, the user is given 5 minutes to pay for the reservation.
- If the reservation is not successful, the user is given the option to be added to the wait queue.
- If payment is successful, the seats are successfully assigned to the user, and a ticket identifying the reservation is generated and sent to the user.
- If the user doesn’t make a payment within the allocated time, the booking and rows linking the seats to the booking are expired (see bitemporal tables here) to indicate that the booking has expired.
- See more on ensuring data consistently in the data consistency section.
- See more on error handling related to payment processing in the payment processing section.
When a reservation for a movie fails due to insufficient seats being available, the user will be given an option to get added to a wait queue.
The user will continue to wait in the queue for a pre-defined time (i.e., 30 mins) until enough seats become available for the user.
When a reservation expires, seats will become available for a show. The process will:
- Send a message over a queue where a service will pick the notification about seats becoming available for a show.
- The process will then determine the earliest user in the wait queue, who can be satisfied with the set of seats becoming available. The process can utilize a distributed cache construct such as a Redis sorted set to determine the rank (time-based order) in which users were added to the set.
- It can utilize a distributed lock by acquiring it from a coordinator service such as ZooKeper and then getting a sorted set of bookings waiting for seats.
- Finding the earliest booking that can be reserved, removing it from the Redis sorted set.
- Releasing the distributed lock
- Changing the state of that booking in the database to Wait-Acknowledgement and thereby decreasing the number of available seats for the show
- Sending the user with that booking a notification that the user can continue with the booking. We can give the user 30 seconds to initiate the booking, after which we can expire the booking and move to the following user.
- The reason to use a distributed lock via ZooKeeper is so that if another reservation expires at the same time and another process tries to find a waiting user, the two processes don’t end up in a distributed race condition – notifying the same user twice or miscalculating the number of available seats.
Why use a distributed in-memory cache
- The given volume of the read and write traffic for reservations can be handled without a distributed in-memory cache. Hence I havent added a distributed stateful cache in this design. However, if the scale of a read and write traffic grows we can utilitize a distributed in memory cache to serve read queries from the distributed in memory cache.
- The reason to avoid using a distributed in-memory cache for reservations, if possible, is that it adds a good deal of complexity to the echo system – managing consistency between the database and distributed cache is tricky and prone to errors.
- If we use a distributed in-memory cache, we can have a primary distributed cache and a replicated secondary cache. The reason to replicate the cache is to add resiliency to the system. In addition, we can shard the distributed cache to enable increased scale and resiliency.
- In our current design, we are leveraging a distributed in memory cache to serve users waiting for a show from the distributed in memory cache. The reason to utilize a distributed in memory cahce here is that for shows which are very famous, many users will likely get added to the wait queue and managing a consistent wait queue via utilizing transactional consistency in a database will add heavy load on the DB.
- It is constructive to store the movie-related data in a distributed cache since this cache is primarily read-only. While reviews and ratings for movies will change, having out-of-synch reviews and ratings slightly in cache is toleratable.
Asynch processing to clear pending reservations and queues
Run the async job to clear out pending reservations that haven’t been acted upon in more than 5 minutes
- The reservation process can register a timer-based event call back to clear the reservation when the allotted time has lapsed – 5+ minutes.
- To cover against the scenario where a process that had made the reservation crashes, we can have a background process that runs async (every 1 minute) to clear out reservations from the system that have not been cleared in the lapsed time + delta (2 mins for example)
Run the async job to clear out pending waits in the queue that have been waiting for more than 30 minutes
- Users are added to a wait queue (i.e., Redis sorted set) in a distributed cache.
- A background process can run every 1 minute to clear out users who have been waiting for shows for more than 30 minutes (allotted wait time).
- When processing payments, we have to set up the process such that double charges or erroneous loads on the payment infrastructure are not created.
- The design could entail using unique keys per booking – “booking id.”
- And ensuring that retriggering requests for payments for the same key will return in a no-op operation – i.e., make the call idempotent.
- We can store the payment state in a database based on a key (booking id).
- If a subsequent request for the same booking id is received, we don’t repeat the call to the payment infrastructure.
- Inside 3rd party payment systems such as stripe, the concept of idempotent transactions exists where subsequent calls for the same idempotent key don’t result in a duplicate charge. We can leverage this concept when making calls to the payment infrastructure.
- We can divide failures as retriable or permanent. In case of retriable failures, we can make subsequent requests but ignore the retries in case of a permanent failure, such as if the user credentials in the transaction are incorrect.
- To avoid double charges, we can design a system that takes a lease on the booking id and waits for the lease to expire before another payment attempt for the same booking is allowed to pass. This is to avoid cases where the user double clicks by mistake.
- See an excellent article from Airbnb below in references that describes how they avoid double charges.
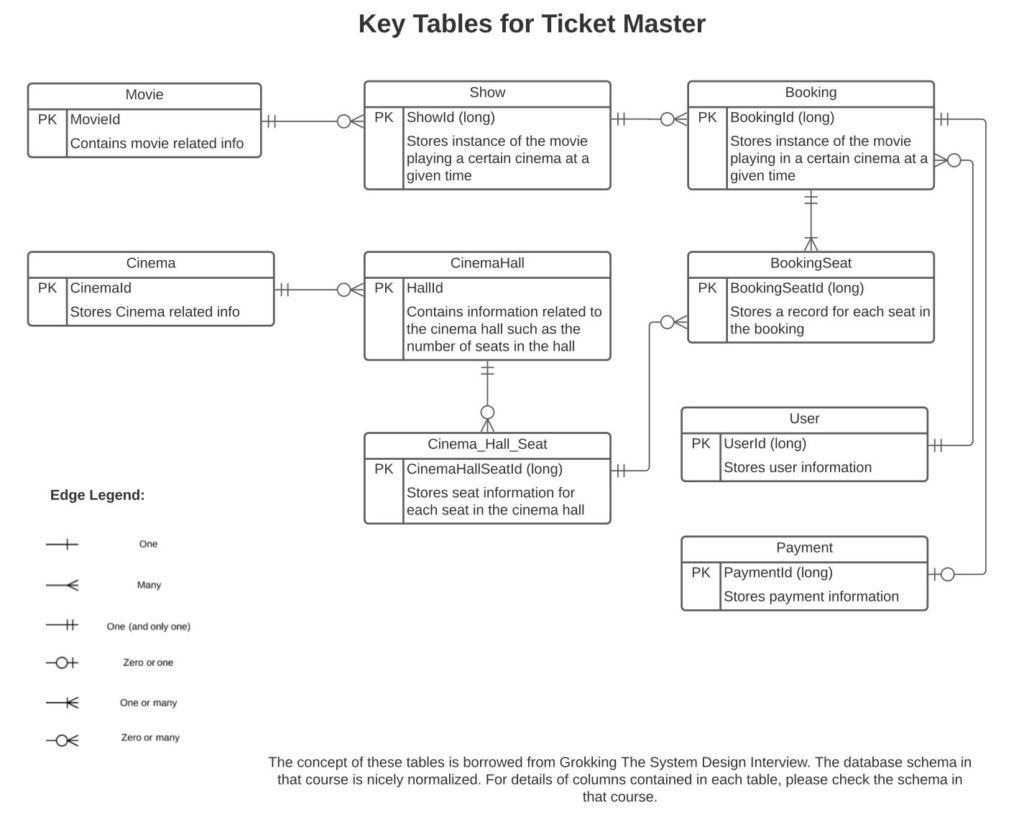
Database partitioning and replication
- We can store the data in a relational database such as MySql as it will serve the ACID transactional guarantees in a well-understood form.
- We can have the primary database run in Active/Passive mode to create resiliency in case the Active database crashes (the passive database becomes the Active while the database that just crashed is restarted).
- We should direct write queries to the primary database.
- We can set up replication in the primary database and direct read queries to the secondary (replicated) database. This is to decrease the load on the primary database.
- A slight issue with this approach is that the read queries may be slightly out of date. But this is a toleratable issue since bookings (writes) will be directed at the primary database.
- We can shard the data over the hash of show id to distribute the queries evenly amongst the shards.
- The reason to not shard over movie id is to avoid heavy traffic on shards that are processing famous movies.
https://www.educative.io/courses/grokking-the-system-design-interview/YQyq6mBKq4n