Consistent hashing is a great way to distribute work in a distributed system. Some of its use cases are in load balancing and in caching. Its key features are:
- Distributes work evenly across nodes
- Enables repeated request to be assigned to the same host
- When new nodes are added, requests from prior nodes are evenly distributed on the new node
- Enables even distribution of work on working nodes when one of the nodes dies
It utilizes hashing to assign requests to the same node. Since repeatedly calling hash on a key returns the same value, this can be utilized to ensure that the same node processes repeated calls of the same request. Another feature of hashing is that it returns a uniform distribution of the hashed values.
The logic works simply as:
- For each node in the system, you create K replicas. For each of the K replicas, you hash the node id and the replica id to create a hashed id for the node/replica.
- You store the hashed id and corresponding node in a tree map. Treemap so you can search for a certain id and find the next highest id in the map.
- For each request, you hash it and look in the map for the next highest value.
Why do we need K replicas per node? In the absence of the replica’s requests are not evenly partitioned between nodes. Imagine a ring with 3 nodes as below. Without the replicas, most requests are processed by node 1 as requests get hashed in the region that corresponds with node 1.
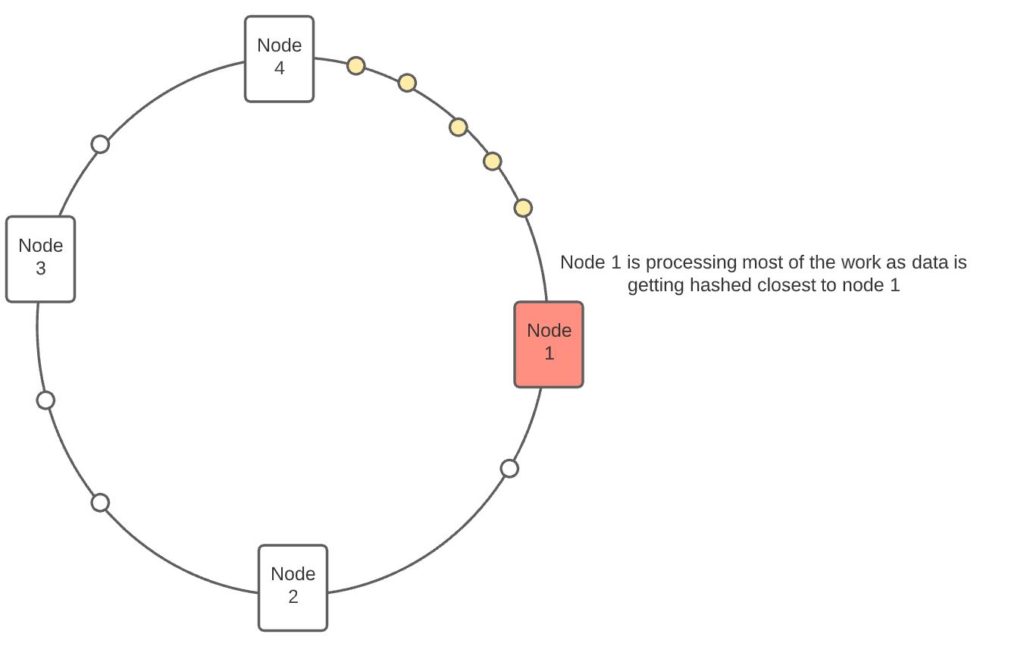
Now let’s change the design to create 3 replicas per node. See that the requests get distributed across more nodes because the gap between two consecutive hashes has been reduced.
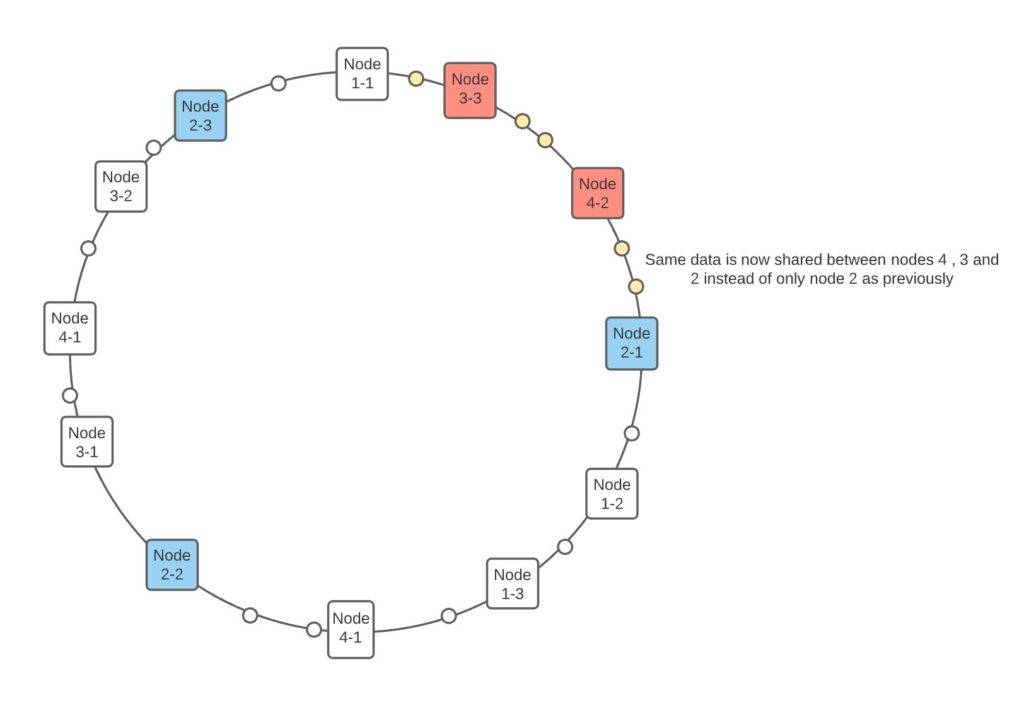
Another excellent feature about consistent hashing is that as you scale up or down the nodes, work continues to get evenly distributed across the nodes since replicas are positioned evenly across the ring. See above, when node 2 dies, the work will get distributed between nodes 1 and 3, instead of being taken by a single node altogether. The distribution gets more balanced as the number of replica nodes is increased as the standard deviation of how far the nodes are spread decreases.
The below snippet of code shows how nodes and replicas are added to a hash ring. And how the node which maps to the hash ring is retrieved.
//a hashing function
private final Function<String, Long> hashFunction;
//using a tree map for hash ring so we can find the next id in //the map greater than a given hash id
private TreeMap <Long, Node> hashRing = new TreeMap<>();
//add replicas for a node into hash ring
public void addNode(Node node) {
for (int i = 0; i < replicas; i++) {
final var hash = hashFunction.apply(node.getName() + i);
hashRing.put(hash, node);
}
}
//hash the request and map the hash to an appropriate node
public Node getAssignedNode(Request request) {
final var key = hashFunction.apply(request.getId());
final var entry = hashRing.higherEntry(key);
if (entry == null) {
return hashRing.firstEntry().getValue();
} else {
return entry.getValue();
}
}
References:
https://en.wikipedia.org/wiki/Consistent_hashing
https://tom-e-white.com/2007/11/consistent-hashing.html