I will provide here a brief introduction to the design and architecture of Cassandra as means of covering how a distributed NoSQL datastore can be constructed. I think it’s imperative to understand the concepts covered in Cassandra’s design as these concepts will serve well in distributed systems designs.
Besides Cassandra, some other distributed systems that should be carefully studied are ZooKeeper, Kafka, GFS (Google file system), BigTable, HDFS & CockroadDB (open-source alternative to Google Spanner) among several others.
Contents:
- High Level Design: See here the high level design of Cassandra
- Data Storage: See here Cassandra’s data storage
- SSTable Storage: See here specifics on SSTable data storage
- Data replication: See here for Cassandra’s data replication
- Data consistency: See here for how Cassandra ensures data consistency
- Write path: See here an explanation of data write path in Cassandra
- Read path: See here for data read path for Cassandra
- Managing cluster state: See here for how Cassandra manages its cluster health state via gossip protocol
- Handling deletes: See here for how Cassandra manages deletion of data
- Transactional support: See here for Cassandra support of light weight transactions
- Additional interesting items: See here for additional components in Cassandra such as Snitch, Partitioner, Data-compaction, Merkel Trees and Data Versioning
- Source code: See here for link to Cassandra’s source code
- References: See here links to several external references which I used to construct this arcticle.
High-Level Design
Cassandra serves as a distributed database that supports fast writes and has replication and redundancy built into its design. Its use cases are for applications such as IoT devices which require fast writes, exchange stock price tick data (time series data), and other general cases where data is rarely updated and data can be partitioned across a key such that nodes can have an even distribution of data.
It uses a consistent hash mechanism to store and service data. See more on consistent hash design here. In essence, data is mapped to a node by a partitioner where a node stores a range of data. In addition, Cassandra can be configured to replicate the data on other nodes in the same data center or across the data center. It has a very efficient data write mechanism which suits fast writes.
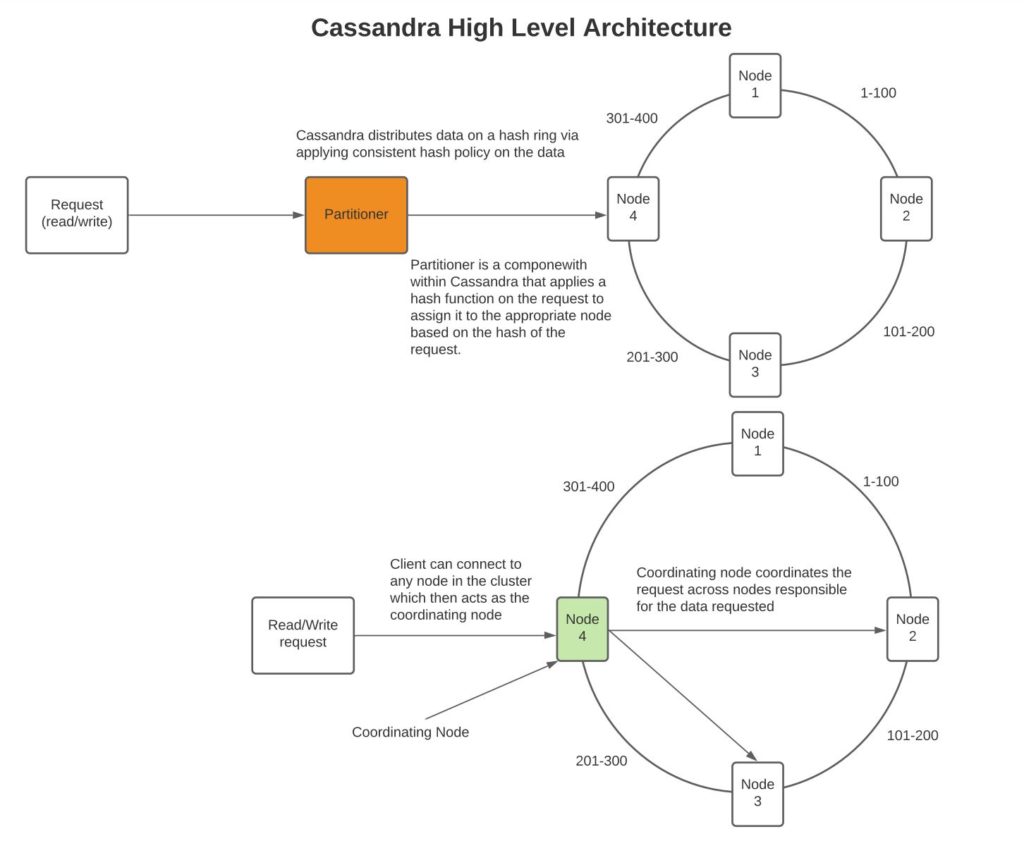
Data storage
- Commit log: Commit log is the append only write-ahead log into which writes are wriiten. Its physically stored on the filesystem. Its use case is to enable fast writes via its append only feature and to provide data durability if the node crashes before stroing the data into SSTable (mentioned below). When a node restarts it recovers its state via the commit log.
- MemTable: Memory table is an in memory representation of the SSTable. Memory table provides reads for data thats yet not flushed into SSTables, once the size of memory table reaches a threshold it is flushed to disk asynchronously upon which a new memory table is created. Data in MemTable is sorted by the order of partition and cluster keys.
- SSTable: SSTable is the physical storage into which cassandra writes its physical data. SSTables are immutable.
- RowCache: RowCache cache is an optional feature which can be used to cache frequently read rows. It stores a complete data row, which can be returned directly. RowCaching is great for read performance at cost of greater memory utilization – GC in the java JVM needs to be carefully tuned to prevent heavy GC load.
- KeyCache: KeyCache stores map of keys to their compression offsets which can be used to quickly return the data. KeyCache consumes less memory as it only stores offsets to data rather than actual data.
- ChunkCache: ChunkCache is stored in off heap memory to store uncompressed data chunks off of the SSTable data. Thus if data exists in the chunkcache it can be quickly returned to the caller without fetching it off of the disk.
- Partition Index Summary file: Partition Index summary file contains partition range and byte offset mapping to the partition index file. Its a smaller file thats stored in memory.
- Partition Index file: Partition index file contains a mapping to the partition key and the byte offset of the partition in the physical data file. Thus partition index file enable fast lookup of the data via enabling data to be loaded off the data offset in the file and thus prevent scanning the whole data file.
- Data file: The physical data is stored in data file based off of partitions and rows inside the partition. Paritions are physically stored in a form ordered by the partition key.
- Bloom filters: Each SSTable has an associated bloom filter that can be used to effeciently return whether data may exist in the SSTable or if it absolutely doesnt exist in the table. Thus bloomfilters can be effeciently used to check for the possibility whether data may exist in a table or is definitely missing. In addition, bloomfilters take very little memory and thus can be stored in the process memory. See more on bloomfilters here.
- SSTables compression: SSTables can be compressed with various options – more on the options can be found here. See below on compaction regarding how SSTables are merged.
Data replication
A beautiful feature of Cassandra is that replication is inherently built into Cassandra’s architecture. Unlike typical relational databases, there is not a single or multi-master, any node can process the data while ensuring it gets replicated to other nodes based on the configuration. This is a very powerful feature in that data replication and redundancy don’t have to be designed as an afterthought.
Replication in Cassandra is based on a combination of the replication factor and replication strategy. The replication factor indicates the number of nodes that will receive and store the replicated data. Cassandra supports multiple replication strategies, the simplest is where data gets persisted into the node selected by partitioner and then replicated to the next N (replication factor) consecutive clockwise nodes. Another replication strategy is a topology-based strategy where data gets replicated on the next consecutive nodes that are not on the same rack (considering failures are typically on all nodes in a rack). In addition, this strategy allows data to be replicated across data centers where the replication factor per data center can be configured. See more on Cassandra replication strategies here and here.
Data consistency
Data consistency for reads and writes in Cassandra can be tuned. For example, we can for writes specify a data consistency of One, Two, Three, Quorum, Local_Quorum, Each_Quorum, and Any. You can see more about these consistency levels here.
An appropriate consistency level can be set based on the use case, for example, if we are interested in highly consistent writes across data centers and are able to pay for increased latency, we can use the consistency level as Eeach_Quorum which will ensure that writes are done on nodes >= (Replication-Factor/2 + 1) on each of the data centers. Or we can choose Quroum which ensures quorum across the universe of replicated nodes across data centers. Or if we want to pursue fast write speeds and are willing to possibly lose some data then we can use a consistency level of ANY which will process a successful write when one or more nodes write the data.
For reads, similar to writes we can choose an appropriate consistency level. Reads support all consistency levels that are supported in writes except for Each_Quoroum (as latency in each quoroum is the highest).
If we set up our read and write consistency levels such that R + W > RF then we will ensure strong consistency. Here R is the number of read replicas that are read, W is the number of write replicas data is written to and RF is the replication factor.
An interesting feature that Cassandra implements is that when processing reads from nodes, it detects which nodes have stale data and performs a read repair on those nodes. Read repair is performed asynchronously in a background thread while returning the data to the client as soon as it’s been collected and merged across nodes (merge to get the latest set of columns across nodes).
Write-Path
The order in which writes are processed is described in the below diagram.
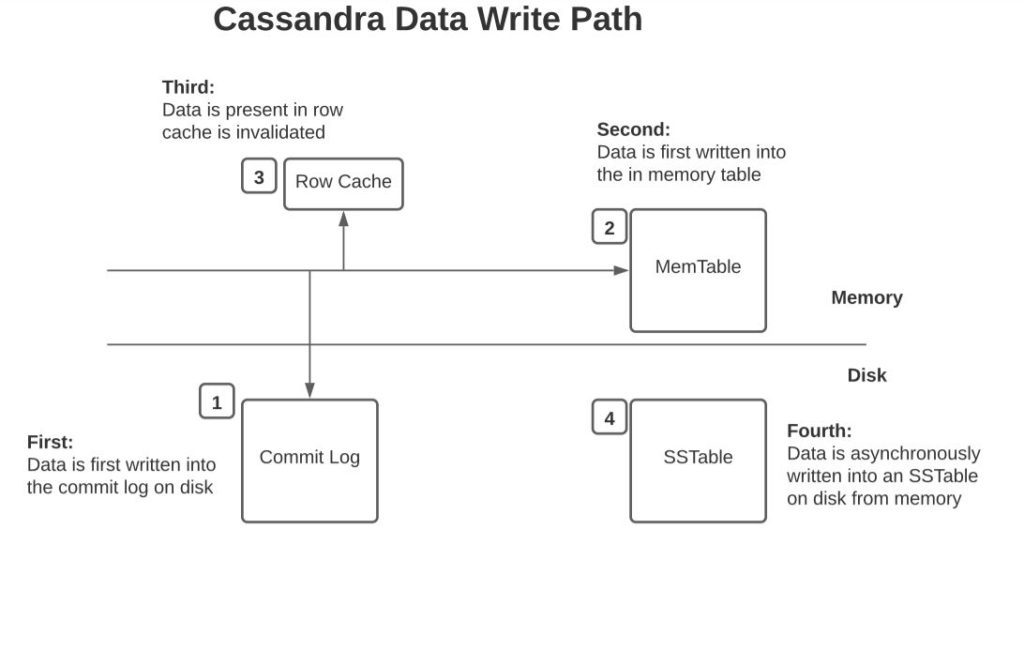
The write is first written into the commit log. And then flushed to MemTable. Once the MemTable reaches a threshold it is persisted into an SSTable. See more information on each of these in the section on data storage above. If a replicated node on which data needs to be written is down, Cassandra writes the hint to another replica node that is alive that the hint needs to be transmitted to the replica which was down once it’s back. Hints don’t count towards write consistency except for the consistency level of “ANY”. See more on hinted handoff here.
Read-Path
For the read path execution flow, please see the below diagram.
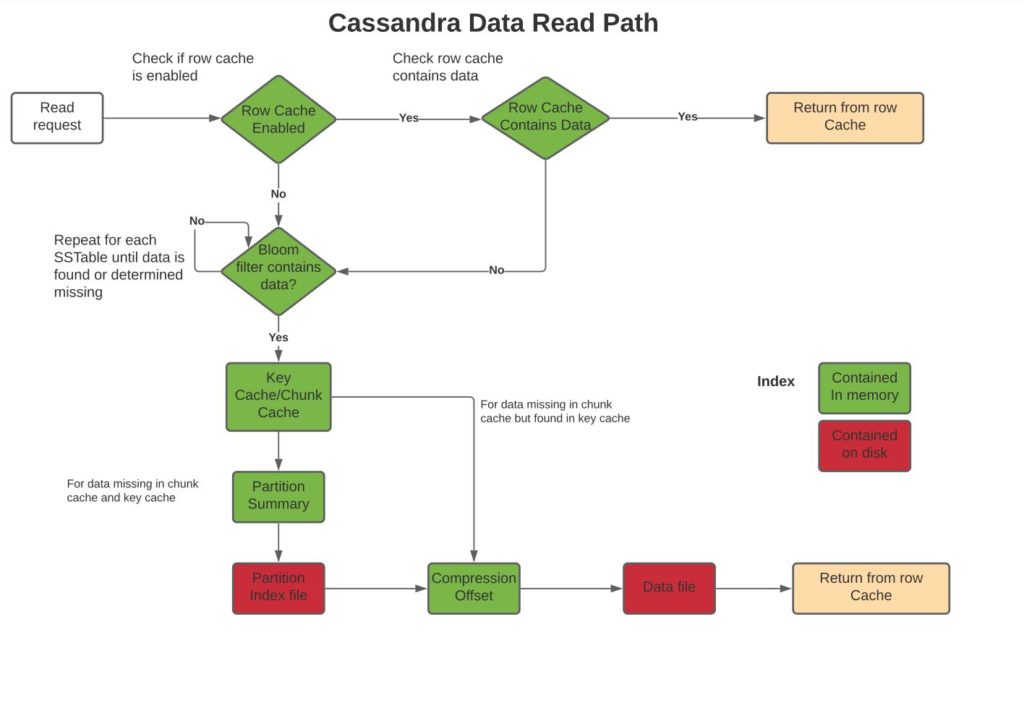
As indicated in the diagram, the order of execution per node in the read path is as below. More on this can be found here:
- Check read from memtable
- If row cache is enabled and key found in row cache , return it
- For each SSTable, via the bloom filter identify whether its possible for the data to exist in the table
- If data seems to exist in the ssstable, check key cache to map to the compression offsets file
- If key doesnt exist in the key cache, check data via partition index summary
- Read data from uncompressed chunk if present in uncompressed chunk memory, otherwise read from datafile.
- If data is not present in uncompressed memory, check for it in partition index file which maps data to the compression offsets in the data file
- Read data from the data file
- If data isnt found in the any of the SSTables return it as not found
Managing cluster state
Rather than a single service that’s responsible to manage the health state of various nodes and thus become a single point of failure or cause performance degradation if work for health management is distributed across specialized nodes, Cassandra chooses a gossip-based design. Nodes communicate health information with other nodes and while communicating they exchange the state of health information they each previously contained and thus obtain the combined up-to-date health information.
Cassandra does give the option to allocate some nodes as seed nodes which are designed to facilitate bootstrapping of the gossip process for new nodes joining the cluster.
Cassandra uses a Phi Accrual Failure Detector to analyze the health state of nodes which identifies a numerical ranking for health rather than binary good or bad. Based on a node’s health ranking Cassandra can skip communicating with the node whose health state is weak to provide good performance.
See below in references an excellent video by an Apple employee who describes how Cassandra manages the health state of the cluster via a combination of gossip protocol and Phi Accrual Failure Detector.
Handling deletes
As discussed above Cassandra is engineered to support fast writes and it does that by ensuring writes are append-only. In addition, SSTables into which physical data is written are immutable. Hence, Cassandra per its design cant physically delete data from existing SSTables. Lastly, Cassandra is a distributed database and thus nodes containing replicated data may not be reachable at the time of the delete and thus could miss the delete notification. Later when those nodes come online they can propagate their state to other nodes which had the data deleted and thus cause the deleted data to reappear.
To manage deletes correctly per its design, Cassandra tags data that is deleted with a certain marker called “tombstone” without physically deleting the data. Tombstones are removed as part of compaction, where compaction on tombstone-based data will run only after a tombstone’s expiry time has passed. The expiry period for tombstones is introduced to give offline replicas time to recover and reconcile missed updates and deletes.
Transactional Support
Cassandra does not provide complete transactional support such as that available in relational databases such as MYSQL. Cassandra does provide lightweight transactions which allow you to do an insert or update operation based on an if condition. Internally Cassandra uses the Paxos algorithm to reach a consensus before applying the operation. However, lightweight transactions don’t scale very well under a large load. See more on lightweight transactions in Cassandra here. Here is an interesting comment someone posted on how Cassandra manages state when a lightweight transaction is reading that that is being modified in another transaction.
Additional interesting items
- SNITCH – This is a very interesting concept implemented by cassandra where a feature called “SNITCH” is used to examine the network topology – performance of read and write requests from one node relative to another and the overall health of nodes such as which nodes are performing poorly. Based on this information Cassandra can delegate read and write requests to nodes which it expects to respond the quickest.
- PARTITIONER – As we discussed above, when a request is received by a node, it hashes the key of the request to dertemine which node is responsible for processing the request. The component responsible for dermining the distribution of data (hash based division) amongst the nodes is called Paritioner. Cassandra provides multiple hash algorithms to choose from and in addition users can supply their own.
- Data compaction – As discussed above in storage once the size of MemTable reaches a certain threshold they are flushed to disk. In addition we saw that deletes are really “soft deletes” – soft in that meta data is attached on a deleted row (tombstone) to indicate that they are deleted but the data is infact not deleted. Therefore cassandra has a feature called compaction where based on a compaction policy the deleted data is physically removed and data from various SSTables is merged together into a compacted SSTable. Cassandra supports multiple compaction strategies which could be set based on the application use case such as support fast reads, conserve physical space or persist data based on time window (for time series data). More on these compaction strategies can be found here.
- Merkel Trees – Due to asynchronous replication data between nodes maybe out of synch. In order to synch the data between nodes, and in order to reduce network IO during the synch, instead of synching the entire data set between nodes only the missing data is synchronized. This is done via utilizing Merkel Trees. A Merkel Tree is a hash tree (similar to a binary tree) where each node contains the hash of its direct children. This can be utilized when comparing trees to detect tree sections which mismatch and thus only synchronize the mismatched parts. See more on Merkel Trees here.
- Data Versioning – Cassandra internally stores a timestamp with each column of a row. This allows Cassandra to handle conflicts where Cassandra is setup to let the last write win. While providing reads data from different replicas is compared and latest columnar data per row across replicas is returned. Amazon’s Dynamo uses vector clocks to compare data versions. Dynamo is a key/value store so a single version of the value works well for Dynamo. However, Cassandra is a wide column data store and thus needed more fine tuned columnar level versioning. In addition, Cassandra’s developers gravitated to a simpler design of allowing the last write to win instead of pushing the conflict back to code to resolve. See here a video from Martin Kleppmann explaining lamport and vector clocks.
Source code
Cassandra’s source code is elegantly written and can be understood by focusing on one topic at a time (i.e. peeling an onion). You can download it from Github here. Highly encourage you to spend time with the code.
References
Describes the high-level architecture of Cassandra
https://cassandra.apache.org/doc/latest/cassandra/architecture/index.html
Another in-depth article on Cassandra’s internals
https://docs.datastax.com/en/cassandra-oss/3.x/cassandra/dml/dmlDatabaseInternalsTOC.html
Zippy DB is a Facebook distributed Key-Value store that provides transaction guarantees. It’s a nice read on this subject.
Describes rocks DB – a persistent key-value store
https://www.facebook.com/notes/10158791582997200/
https://github.com/facebook/rocksdb/tree/main/java/src/main/java/org/rocksdb
Describes Cassandra’s gossip protocol
Here is an article where the author describes some things he doesn’t like about Cassandra
https://blog.pythian.com/the-things-i-hate-about-apache-cassandra/
A brief high-level overview of lightweight transactions in Cassandra
https://blog.pythian.com/lightweight-transactions-cassandra/
Uber moved away in recent areas from Cassandra to an internally built data store called schemaless and to Google spanner. Their engineering blog states the reason for the move was that for their business case and scale Cassandra didn’t work well due to its limited capacity in handling a high load of transactional requests and secondly gossip didn’t scale well when the number of nodes in a cluster increased beyond one thousand.
https://eng.uber.com/schemaless-sql-database/
https://codecapsule.com/2012/11/07/ikvs-implementing-a-key-value-store-table-of-contents/
Cassandra Proposed Enhancements
https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=95652201