Below I will describe how to build a video content servicing platform such as Youtube.
Content:
Requirements: Discusses requirements of the design here
Capacity and storage estimation: Discusses back of the envelope estimation for the design
High-Level Design: Discusses High-level design blocks
Upload Videos: Discusses the process of uploading videos
Video processing on the backend: Discusses the process of video processing on the backend
Clientside Video Streaming: Discusses streaming videos on the client-side
Content servicing: Discusses how content is pushed to edge servers which stream content to client devices
Optimizations: Set of optimizations done to create efficiency in the system.
References: Mentions various references used in coming up with this design
We will support multiple client devices: Mobile Phones (Android, iPhone), Browser
Our users will be located across geographic regions (US, Europe, Asia, South America, Canada, Etc)
The focus should be on ensuring high scale, low latency, and resiliency.
We should support adaptive streaming and the highest possible bit rates.
We will not cover video sharing and video search in this design. In addition, we will not cover video rights management. You can view the concept of sharing files in the dropbox file system design here. In addition, I will cover the content search in a separate article.
Capacity and storage estimation
Total numbers of users: 1 billion.
Daily active users: 5% of total = 50 million.
Average videos uploaded per user daily: 5 videos.
Average video compressed size: 10 MB
Daily storage space growth: 50m * 5 * 10MB = 250TB
Yearly storage growth: 90 PB
Assuming 5% of the daily active users are concurrently streaming, it means that we need to support 2.5 million concurrent users. Assume on average, streaming video content takes 1Mb/sec (could vary from few few hundred Kbits/sec to several Mb/sec depending on the quality of the stream), supporting 2.5 million concurrent users will consume 2.5Tbs/second. Assuming a large data center has maximum bandwidth capacity of 100Gb/sec, it will take 25 large data centers to support this load. To scale the load further would be troublesome because creating large data centers is more resource intensive. Another solution will be to use an Edge/CDN provider such as Akami or build a similar edge network ourselves. Assuming one edge can handle 3Gb/s, we will need 1K edge servers to support this load. Borrowing the distributed network design concept from Akami (see references), we can build a tiered network with a few large data centers at the top, 10s of regional data centers under the large data center, and edge servers close to the end-users. This will help alleviate network lag by decreasing load on the middle network (between the data center and client ISP) and enable us to quickly build up capacity if needed as adding more edge servers is easier than adding data centers.
Video upload bandwidth should be significantly smaller than that of content streaming. We can upload videos straight to the user’s originating Tier 1 data center while utilizing cloud storage near the user as an intermediatory location.
Users will be able to upload videos from their devices. Video uploads should be supported across an array of network bandwidths (fast, medium & slow).
Users should be able to stream videos from the service.
At a high level, the process is broken down into a module that manages video upload, another module that encodes the videos into various bit rates and formats, and lastly a module that provides video streaming service to the clients.
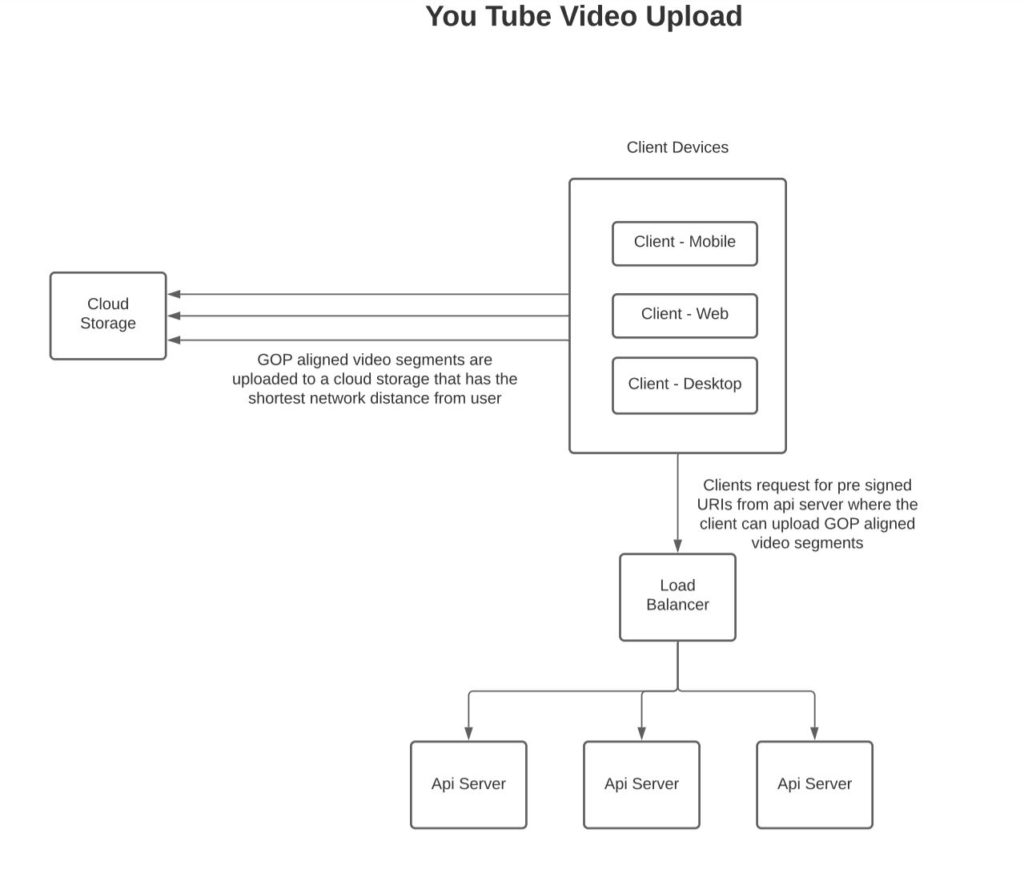
As part of uploading the videos, the clients will analyze the video based on its content, size, and quality and determine chunks into which the video can be split. Each chunk will be a separate video segment (0.5 seconds to 10 seconds) depending on the quality of the video – smaller duration chunks for higher quality videos to keep the size of chunks small. The chunks will be based on a group of picture boundaries (GOP). Each chunk will be an independent segment so that we can process it in parallel irrespective of information in other chunks. See the article below in references from AWS in order to understand the concept of GOP better.
Based on the number of chunks, the client will request a set of signed URIs from the server. The client will in parallel upload the chunks to the URIs. See in references below Microsoft’s concept of signed URIs. The URIs will point to a blob store close to the user.
The reason to upload the videos in small segments rather than the whole file is so that the video can be more quickly uploaded to the server. Imagine a scenario where the network disconnects in the middle of transmitting the large video, the client will have to start again from the beginning whereas when transmitting small segments the client will only need to retransmit chunks that were in the middle of being uploaded.
To reduce the size of data being transmitted the client will compress the chunks before publishing them so as to reduce the data that is transmitted over the network and to reduce the space which the video will consume on the cloud.
Video Processing on the backend
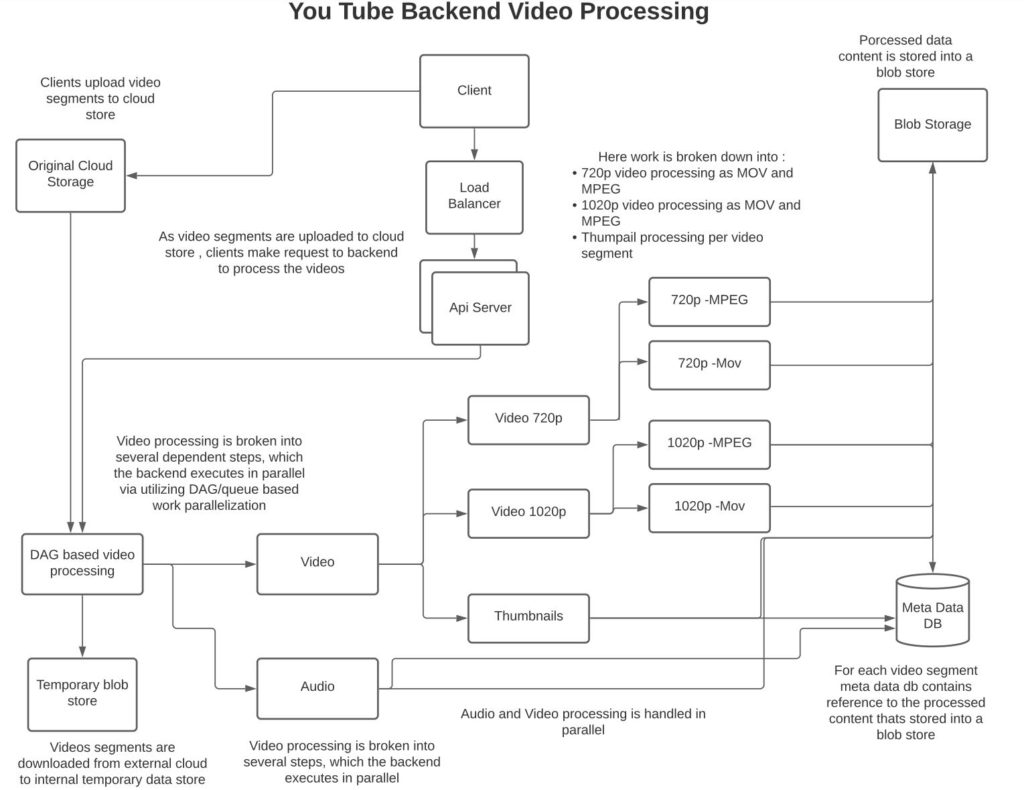
Video will need to be serviced to clients in various formats (MPEG, MOV, etc) and bitrates depending on the type of client and network bandwidth. Hence, the backend will need to convert the original video content into various formats for later serving to the clients.
We could use processing based on a directed acyclic graph (DAG) to:
- Preprocess the segments to ensure the type of content being published is appropriate. In addition, based on the original quality of the content we can determine the bit rates we want the content to be generated in. For example, if the original resolution of content is 720p then we cant generate 1080p or 4k content out of it. But if the original content was 4k, we can generate 1080p and 720p copies.
- Transcode the segents into various bit rates in parallel while storing the various formats and bit rates on a blob storage. We could possibly use an external blob storage such as Amazon S3 for that.
- Store audio from the segments seperately so that the audio can be merged with the video during streaming
- Create thumbnails for each chunk, which can be used to display an image for the chunk to the client
To parallelize the work we can utilize queues to transmit the work units to workers which can process the work units in parallel. The idea to utilize work queues here is to leverage the competing consumer design pattern so as to parallelize the work across a set of workers. Since the work units are stateless they can be processed independently and in parallel.
However, a set of work units together can be grouped as a single larger unit of work and a DAG-based resource manager ensures that the sub-work groupings are completed appropriately. For example, see the diagram below where the VIDEO processing tasks are split into multiple sub-tasks to convert video into 1080p and 780p and further into MPEG and MOV formats.
A persistent queue serves as a good mechanism of work distribution as the queue can be split into workgroups where workers can in parallel consume work units from workgroups (i.e Kafka partitions). In addition, consistency is maintained where work is only pulled off the queue (i.e Kafka offset advanced) when work is completed – video persisted into blob storage. We can design the work units to be idempotent such that no harm is done if a work unit repeats. i.e if a worker crashes after persisting the video to storage but before advancing the offset in the queue, another worker will redo the work but we can design our workers such that repeated execution of tasks has no adverse effect (idempotent). This can be done by assigning unique ids to each work unit and the worker checks before executing the work if the work has already been performed and if it has then it returns success without executing the work.
When a client requests a video, the request will contain the type of video format and a bit-rate based on the client’s device and bandwidth. The service will transmit segments consisting of GOP over a transport to the client. Each segment can be considered a separate part of the video that the client will use to display the combined video to the user while stitching segments together in order to provide a continuous video stream to the client. The client will buffer segments of video that are expected to play in the coming period (5-30 seconds) so that the user isn’t affected by network disruptions.
Based on the time it is taking for chunks to be transmitted from the backend to the client, the client device will adapt the bit rate of videos being requested such that the highest quality of content is displayed to the user without disruptions in the video. For example, if network bandwidth is high the video will be displayed in 4K, otherwise in 1080p or 780p.

Clients communicate with edge servers closest to them. If the edge server contains the content they can deliver it to the client, otherwise, the edge server requests a regional server for the content, if the regional server has the content it will deliver it to the client, otherwise, the regional server requests the content from content originating data center. If multiple requests for the same content are received by an edge server, the edge server queues the content so as to not overwhelm upstream data centers with the same request. As the content becomes available the edge servers will stream it to the clients. The storage capacity on edge servers is limited. Hence, content on the edge servers has a time to live after which that content is deleted from the edge server.

Video upload: While uploading video chunks to the cloud we break the video into small segments each of which we independently and in parallel upload to the cloud.
Video processing: As video segments are uploaded onto the cloud store by the user, we start working on processing the video segments in parallel. We use a DAG-based approach to break the work into smaller chunks each of which can be processed independently and in parallel. We can use queues competing-consumer-based design pattern to put work units onto a queue which any of the consumers can pick to process the work.
Streaming: We provide adaptive bitrate streaming with the goal to provide the highest possible bit rate to the users based on the network and client device.
Content servicing: We can track regional usage and upload the content which is expected to be in demand onto the edge servers before client requests so that client doesn’t have to wait before the content starts to stream.
http://highscalability.com/blog/2012/3/26/7-years-of-youtube-scalability-lessons-in-30-minutes.html
https://aws.amazon.com/blogs/media/part-1-back-to-basics-gops-explained/
https://bitmovin.com/adaptive-streaming/
https://bitmovin.com/digital-rights-management-everything-to-know/
https://www.cs.princeton.edu/~wlloyd/papers/sve-sosp17.pdf
System Design Interview – Alex Xu
The Akamai Network: A platform for high-performance internet applications