- Purpose and Requirements
- High level design
- Storage estimate
- Detailed component design
- Enabling politeness
- References
Purpose and Requirements
Purposes of web crawler could be one or more of:
- Search engine indexing: Search engines need to crawl the web to process search queries
- Web mining: Analyze the content on the web for research purposes
- Web monitoring: Monitor for copyright and trademark infringement
- And other use cases
The design below covers the use case for search engine indexing.
Requirements of the design are:
- Crawl several billion pages per month
- Store the webpage content for a configurable time
- Avoid duplicate URLs or page content
- Be robust enough to handle page content with traps
- Be polite in its processing to not overwhelm webservers
- Extensible in design to process content beyond just HTML
- Prioritize crawling content (i.e. by page rank)
High level design
The below design is structured to break the web crawler’s work into multiple smaller units to gain scalability and simplicity.
Storage Estimate
If we assume 1 billion new pages are processed each month and the size of each page is 200KB then we need 200TB of storage per month. This amounts to 2.4PB of data yearly, if we store data for 10 years it amounts to 24PB of data.
Assuming 1 billion pages per month, it amounts to ~350 QPS. The highest compute load will be on the content parsing service, assuming a single commodity server can handle 48 parallel compute threads and planning for ~40% of peak load per server, we can assume a single server can handle 20 QPS. Hence, we will need approximately 20 servers for content parsing.
Detailed Design Components
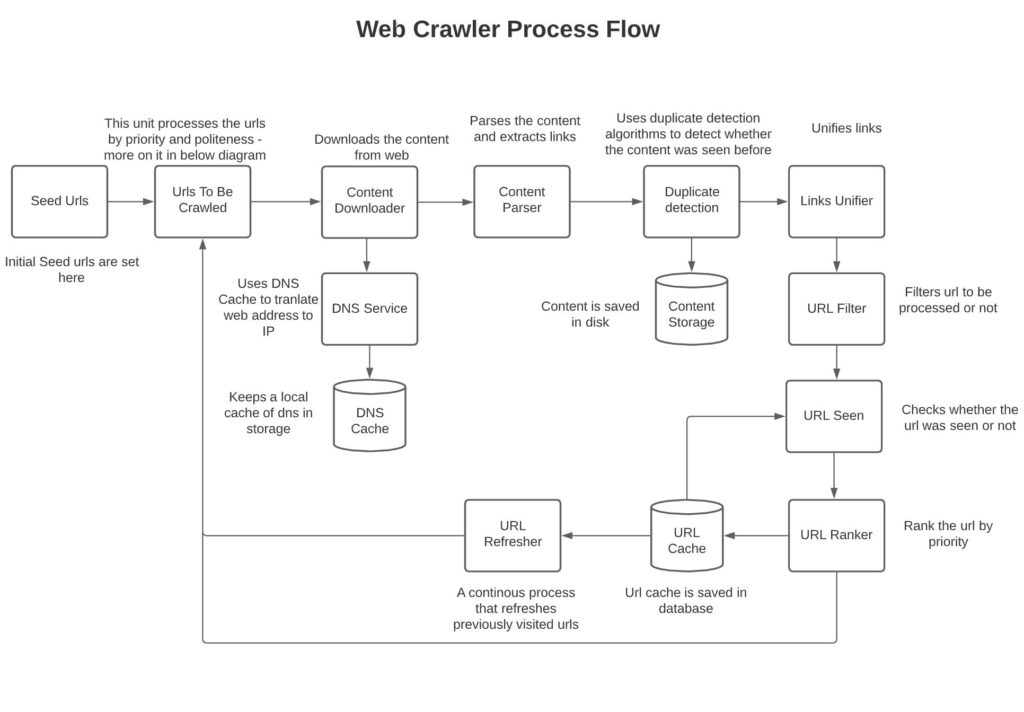
Here I describe each of the components in the above diagram in more detail.
Seed URL:
These are the starting URL addresses based on which the www traversal will begin. The starting URLs can be based on topic, region, etc.
Urls To be Crawled:
This is a set of queues identifying the URLs which need to be crawled; more on it below.
Content Downloader:
Content downloader queries the DNS service to translate the domain to an IP address. It then downloads the page content from the WebHost. Content downloader runs across a series of machines and multiple threads per machine. This is an IO-intensive task; therefore, running multiple threads per host and distributing work across hosts makes sense. Content downloaders can run as stateless processes taking work from a distributed queue such as KAFKA and downloading the content which they can write to a key-value store. And publish a pointer to that store over KAFKA queues again for the content parser to process.
DNS Service:
The DNS service transforms the domain to an IP via using the DNS cache. If the domain isn’t available in the DNS cache, it calls the DNS resolver to transform the domain to an IP. The motivation to use a DNS cache is because calls to a DNS resolver are slow. Standard DNS lookup libraries are single-threaded. Hence, utilizing a DNS cache and an asynchronous interface will lower the latency which will enable significantly higher throughput. As an example, if a single-threaded DNS lookup results in 10ms per call, it will process 100qps per host. If we lower the latency by utilizing a DNS cache to 4ms and parallelize requests across threads, assuming a commodity machine has 12 cores that are able to run 8 threads per core, we will be able to process per thread 250qps and assume 96 concurrent threads per host, this turns out to approximately 25K QPS per DNS host.
Content parser:
The content parsing is done in a process distinct from that of the content downloader. This is because interleaving parsing of content inside the IO calls will make downloading the content very slow. The content parser will pull a parsing request from the Kafka queue, load the content from storage and then parse the data.
The intention of the parser is to parse the page and extract the HTML or other content (images, videos, etc.). Content parsing should be parallelized across several machines as it’s a memory and compute-bound task that will benefit from increased hardware resources. Content on a webpage can be dynamic such as javascript or ajax based. For such content, it needs to be dynamically rendered rather than statically parsed (see reference). In order to avoid parsing the content twice, the content parser can extract links out of the content and pass them to the link consolidator.
The content parser will need to avoid spider traps that create an infinite crawl (i.e. urs such as www.blah.com/a/z/a/z/a/z…..), advertising content, proprietary data, and objectionable content.
Content Seen:
This validates whether the parsed content was previously not seen. It utilizes one of the matching algorithms such as simhash, minhash, etc to determine similarity in content. See references below for more details on how similarity in content can be determined.
Content Storage:
We will be storing a lot of content, so we need an efficient way to save the content. This can be done in a key-value store such as HBase, BigTable (for google), or amazon S3 on AWS. We can compress the data before storing it in the database to reduce the space used in storage.
Links Unifier:
This service consolidates the relative paths from the link into a single path.
Url filter:
It verifies the link extension is in the interested set of data that needs to be crawled and validates whether the link points to a valid page.
In addition, the URL filter needs to ensure that the URL conforms to parsing rules specified in the server’s robots.txt file which provides a set of rules that robots should follow when parsing content on the server.
Url Seen:
Checks whether the URL was previously seen or otherwise. Can utilize consistent hash to send the URL seen request to an appropriate node that has the bloom filter corresponding to the given hash in memory. See references for more information on bloom filter; it’s a probabilistic data structure that says with confidence whether the URL has not been seen already but can’t say deterministically whether it has been seen already. The data structure is very efficient, assuming the data it’s working with can fit in the cache. Hence, can utilize various nodes to distribute the URL search across hash boundaries via consistent hash mapping to the appropriate node.
Url ranker:
Url ranker uses an algorithm to determine an appropriate rank for the URL. See in references page rank algorithm, which has previously been used by Google to rank pages. The rank is later utilized to prioritize URL fetch.
Url cache:
Url cache stores the URL that has previously been seen along with their rank and timestamp. The URLs can be saved in a distributed database such as Cassandra.
Url Refresher:
Url refresher can process pages that have changed since they were last processed and pass them on to the URLs to be crawled module. We can prioritize freshness based on page rank and time it was last fetched or another policy as appropriate.
Enabling politeness in the web crawler
Enabling politeness and priority (URLs to be crawled): The module labeled ‘URLs to be crawled’ needs to be designed as below to facilitate prioritization and politeness.
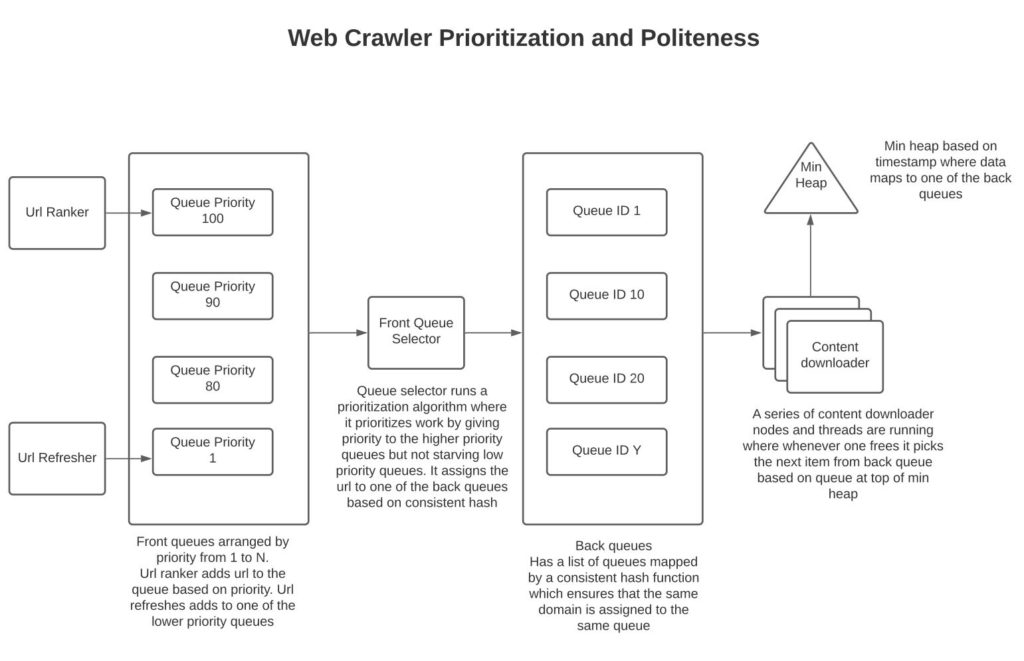
Front queues by priority:
We have a series of back queues by priority where higher priority queues are assigned URLs that have a high rank and are being processed by URL rankers. Items from URL refresher are assigned to queues with lower priority based on the page rank of the URL being refreshed. The rank of a URL can be constructed via a combination of factors such as frequency of page access, percentage of web traffic processed by the server, and page rank.
Front Queue Selector:
The front queue selector gives higher priority to URLs that are assigned to queues with higher priority but ensures that URLs assigned to queues with lower priority don’t starve.
Back Queues:
These are numbered queues from 1 to Y where the front queue selector assigns a URL to a back queue via consistent hash using a hash of the domain of the URL and the hash of the queue to which the URL domain should map.
Min heap:
The motivation of the design is to enable politeness by not re-querying a host without some delay. The logic used here is that the content downloader pulls a queue id off the minheap with the lowest value. Pulls a URL off of that queue and assigns a timestamp in minheap to that queue as current time + delay. Delay can be tuned as the time we want to wait between consecutive page pulls from the host. This will ensure that the content downloader will not stay idle, but the queue just processed will be processed after some delay to ensure politeness. For this approach to work elegantly, the number of back queues should be a factor of times greater than the number of content downloading nodes so as to ensure enough delay between consecutive downloads from the same host.
The above design traverses the pages in BFS order while giving priority to pages with higher rank and ensuring politeness so that we are repeatedly not querying the same host.
References:
A nice design video on web crawler
Lecture notes on web crawler
https://web.stanford.edu/class/cs276/handouts/lecture18-crawling-1-per-page.pdf
Page rank (The PageRank Citation Ranking: Bringing Order to the Web)
http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
Web crawler design paper (By Christopher Olston and Marc Najork)
http://infolab.stanford.edu/~olston/publications/crawling_survey.pdf
Dynamic rendering
https://developers.google.com/search/docs/guides/dynamic-rendering